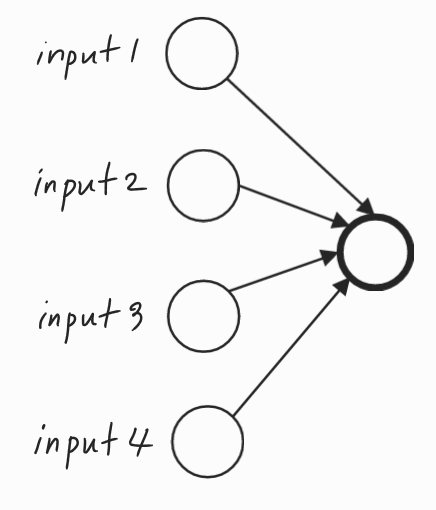
이번 강의에서는 신경망의 뉴론을 삭제하는 이상한 기법인 드롭아웃이 왜 정규화가 될까에 대한 이유를 담고 있는 강의이다.첫 번째 직관은 더 작고 간단한 신경망을 사용하는 것이 정규화 효과를 주는 것이고, 이번 영상에서는 두 번째 직관에 대해서 설명한다.드롭아웃이 정규화가 되는 이유단일 유닛의 관점에서 이 유닛은 입력을 받아 의미있는 출력을 생성해야 한다.드롭아웃을 통해 입력은 무작위로 삭제될 수 있다. 단일 유닛은 특성이 무작위로 바뀌거나 고유한 입력이 무작위로 바뀔 수 있기 때문에 어떤 특성에도 의존할 수 없다.따라서 이 특정 입력에 모든 것을 걸 수 없는 상황이다. 즉, 특정 입력에 유난히 큰 가중치를 부여하기가 꺼려지는 상황인 것이다.그래서 이 네 개의 입력 각각에 가중치를 분산시키는 편이 낫다.가중..