분류 모델 (Classification)
로지스틱 회귀는 분류 문제를 해결하는데 탁월한 해결법이다.
먼저 분류에 대해서 알아보자.
분류에는 연속적인 값으로 예측 값을 유추해 내는 것이 아닌 이분법적으로 예측하는 것이다.
예를 들어보자.
Spam Detection : Spam or Ham
Facebook Feed : Show or Hide
Credit Card Fraudulent Transaction Detection : Legitimate or Fraud
로지스틱 회귀
먼저 선형회귀와의 차이점을 알아보자.
선형 회귀는 연속형 데이터를 예측하기 위한 모델인 반면, 로지스틱 회귀는 특정 범주로 데이터를 분류합니다. 주요 차이점은 출력값의 범위이다.
- 선형 회귀: 출력값은 실수 범위.
- 로지스틱 회귀: 출력값은 0과 1 사이의 확률.
학습 시간에 따른 P/F
학습 시간에 따른 시험 결과가 Pass인지 Fail인지를 예측한다고 해보자.

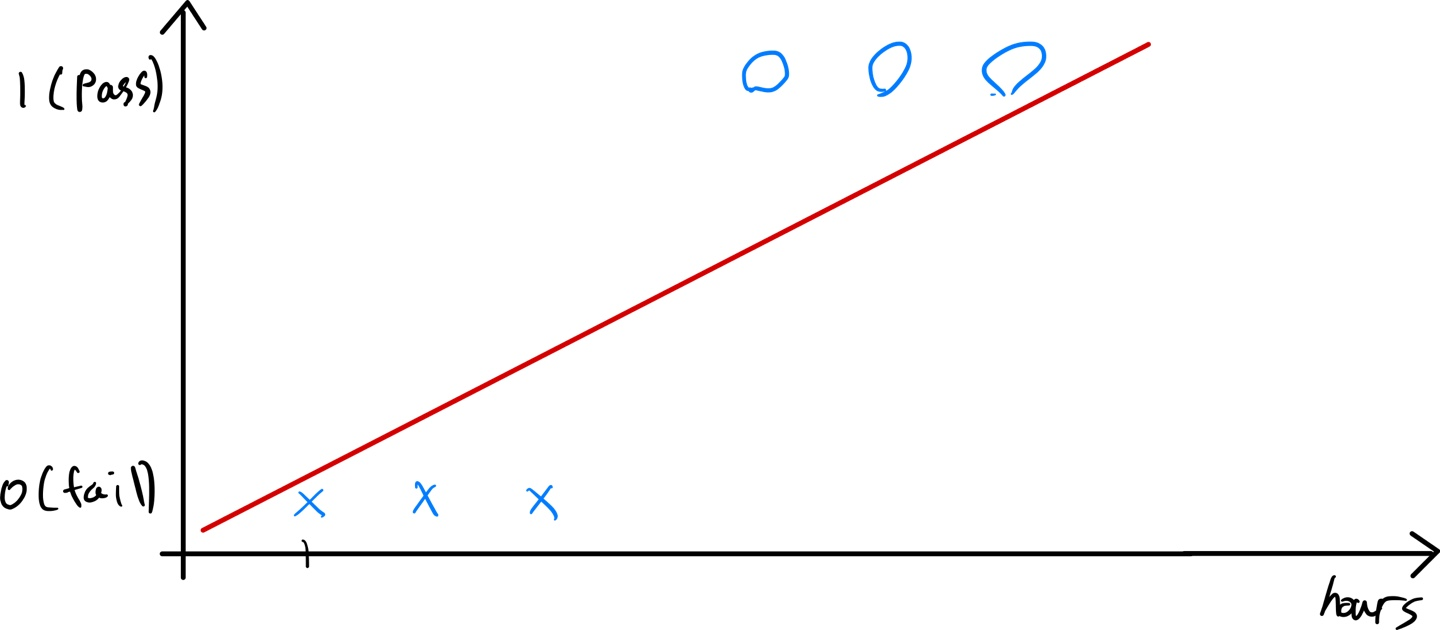
시간이 많이 지날수록 Pass가 되는 것을 볼 수 있다.
이 그래프만 봤을 때는 Linear Regression이 생각날 수도 있다.

이렇게 선형회귀로 가설을 해보면 0.5에 대한 기준선의 오른쪽은 Pass, 왼쪽은 Fail로 분류를 해볼 수도 있다.
이렇게만 된다면 선형회귀를 사용해서 분류 문제를 해결해도 상관이 없을 것 같다.
하지만 문제가 발생한다.

만약에 엄청 오랜 시간 동안 공부를 열심히 한 학생이 시험을 쳤다면 당연히 시험에는 Pass했을 것이다.
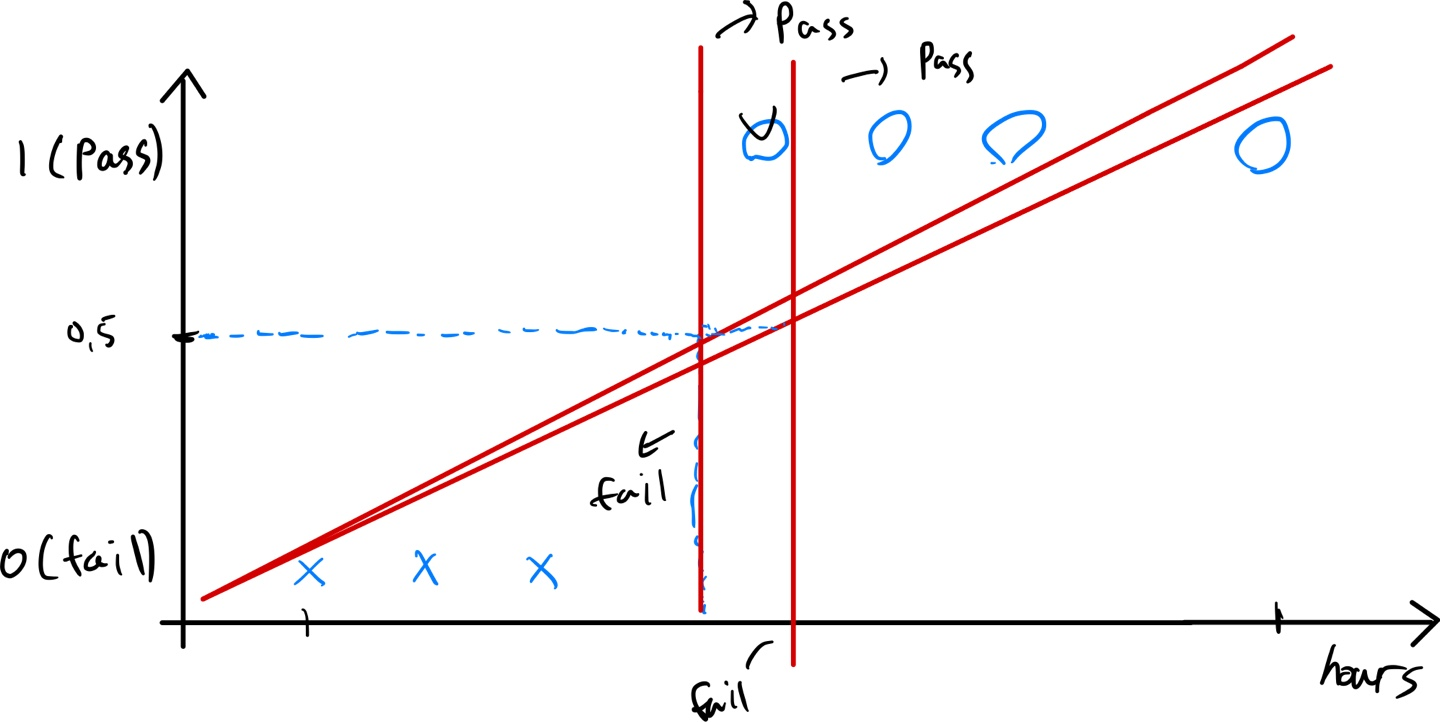
하지만 선형회귀의 예측 함수인 \( h(x) = \omega x + {\small b} \) 에 의해 예측 비용을 최적화하기 위해서는 기울기가 변경될 것이다. 예를 들어 위와 같이 변경되었다고 가정해보면 Pass로 되어야 하는 게 Fail로 잘못 분류되는 것을 알 수 있다.
이를 해결하기 위해서 가설함수는 Logistic function 또는 Sigmod function이라고 부른다.
시그모이드 함수의 역할
로지스틱 회귀의 핵심은 시그모이드 함수를 활용해 입력값을 확률 값으로 변환하는 것이다.
시그모이드 함수는 다음과 같이 정의된다.
$$ \sigma(z) = \frac{1}{1 + e^{-z}} $$
여기서 \( z = \omega x + {\small b} \) 는 입력 데이터 \( x \) 와 가중치 \( \omega \) , 절편 \( {\small b} \) 의 선형 조합이다.
시그모이드 함수의 특징은 z가 계속 커갈수록 1에 가까워지고, 작아질수록 0에 가까워진다.
- \( z \to -\infty \text{일 때 } \sigma(z) \to 0 \)
- \( z \to +\infty \text{일 때 } \sigma(z) \to 1 \)
이를 통해 출력값을 확률로 해석할 수 있다.

의 정의
로지스틱 회귀의 가설 함수는 다음과 같다.
$$ h(x) = \sigma(\omega^T x + {\small b}) = \frac{1}{1 + e^{-( \omega ^T x + {\small b})}} $$
로지스틱 회귀의 비용 함수
로지스틱 회귀에서 평균제곱오차(MSE)를 사용하면, 비용 함수가 비선형이 되어 최적화를 어렵게 만든다. 따라서, 로그 손실(Log Loss)을 사용한다.
로그 손실 비용 함수
로지스틱 회귀의 비용 함수는 다음과 같이 정의된다.
$$ J(\omega, {\small b} ) = - \frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(h(x^{(i)})) + (1 - y^{(i)}) \log(1 - h(x^{(i)})) \right] $$
- 실제 값 (0 또는 1)
- \( h(x^{(i)}) \) 예측 확률값
$$ y = 1 \text{일 때: } \ J( \omega, {\small b} ) = -\log(h(x^{(i)})) $$
$$ y = 0 \text{일 때: } \ J( \omega, {\small b} ) = -\log(1 - h(x^{(i)})) $$
실제 값이 1일 때, 예측을 1로 했다면 \( -\log(1) \) 로 Cost는 0이 된다. 예측을 0으로 했다면 \( -\log(0) \) 으로 발산하게 된다.
실제 값이 0일 때, 예측을 1로 했다면 \( -\log(0) \) 으로 발산하게 되고, 예측을 0으로 했다면 \( -\log(1) \) 로 0이 되는 것을 확인 할 수 있다.
이 함수는 예측값이 실제값과 가까울수록 비용이 작아지고, 멀어질수록 비용이 커진다.
로지스틱 회귀의 학습 과정
로지스틱 회귀는 경사하강법을 통해 비용 함수 \( J(\omega, {\small b}) \) 를 최소화하며 학습한다.
파라미터 업데이트 식
파라미터 \( \omega \) 와 \( {\small b} \) 는 다음과 같은 방식으로 업데이트된다.
$$ \omega := \omega - \alpha \frac{\partial J(\omega, {\small b})}{\partial \omega} $$
$$ {\small b} := {\small b} - \alpha \frac{\partial J(\omega, {\small b})}{\partial {\small b}} $$
여기서 \( \alpha \) 는 학습률(Learning Rate)이다.
Referense
https://www.youtube.com/watch?v=6vzchGYEJBc&list=PLlMkM4tgfjnLSOjrEJN31gZATbcj_MpUm&index=12
https://www.holehouse.org/mlclass/06_Logistic_Regression.html
06_Logistic_Regression
Classification Where y is a discrete valueDevelop the logistic regression algorithm to determine what class a new input should fall intoClassification problemsEmail -> spam/not spam?Online transactions -> fraudulent?Tumor -> Malignant/benignVariable in
www.holehouse.org
'AI > ML' 카테고리의 다른 글
| Prophet으로 시카고 범죄율 예측하기 (0) | 2025.02.17 |
|---|---|
| 모델 성능평가 척도 (0) | 2025.02.11 |
| Dicision Trees (0) | 2025.02.09 |
| 선형회귀와 경사하강법 (0) | 2025.01.24 |