Import Library
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from prophet import Prophet위의 네개의 라이브러리는 데이터 분석 및 시각화 처리를 하기 위해서는 필수적이라고 생각하면 되고, 가장 중요한 것은 시계열 예측을 하기 위한 prophet을 설치해야 한다. 원래 이름은 fbprophet이었는데 지금은 prophet으로 설치해야 한다.
Importing Data
chicago_df_1 = pd.read_csv('Chicago_Crimes_2005_to_2007.csv', on_bad_lines='warn')
chicago_df_2 = pd.read_csv('Chicago_Crimes_2008_to_2011.csv', on_bad_lines='warn')
chicago_df_3 = pd.read_csv('Chicago_Crimes_2012_to_2017.csv', on_bad_lines='warn')`read_csv`로 데이터를 받아오는데 옵션으로 원래 `error_bad_lines=False`를 줬다. 하지만 지금은 deprecated되어 지금은 `on_bad_lines`를 사용한다.

error를 하면 에러가 exception이 발생되고, warn은 경고가 발생하며 해당 라인을 스킵한다.
skip은 경고없이 그냥 스킵하는 옵션이다.
chicago_df = pd.concat([chicago_df_1, chicago_df_2, chicago_df_3], ignore_index=False, axis=0)가져온 데이터들을 하나의 데이털 합쳐준다.
Exploring the dataset
plt.figure(figsize=(10,10))
sns.heatmap(chicago_df.isnull(), cbar = False, cmap = 'YlGnBu')이 코드를 통해 데이터가 없는 값에 대해 색을 칠해준다.

`X Coordinate, Y Coordinate, Latitude, Longitude, Location`이 빈값이 있다는 것을 알 수 있다. 다른 예시로는 `chicago_df.isna().sum()`를 확인해보면 된다.
chicago_df.drop(['Unnamed: 0', 'Case Number', 'IUCR', 'X Coordinate', 'Y Coordinate','Updated On','Year', 'FBI Code', 'Beat','Ward','Community Area', 'Location', 'District', 'Latitude' , 'Longitude'], inplace=True, axis=1)여기서 필요가 없는 데이터에 대해서는 drop하여 없애준다.

그렇다면 데이터프레임이 사진과 같이 나오게 된다.
chicago_df.Date = pd.to_datetime(chicago_df.Date, format='%m/%d/%Y %I:%M:%S %p')데이터프레임 열 "Date"를 재배열하여 datetime을 조립한다.

chicago_df.index = pd.DatetimeIndex(chicago_df['Date'])Date 컬럼을 인덱스로 만들어줘야, 추후에 resample 함수를 통해 원하는 주기로 나눌 수 있다.

chicago_df['Primary Type'].value_counts()`Primary Type` 컬럼의 값들을 값 별로 카운트를 해준다.

chicago_df.resample('Y').size()
연도를 주기로 나눠서 사이즈를 구한다.
plt.plot(chicago_df.resample('Y').size())
plt.title('Crimes Count Per Year')
plt.xlabel('Years')
plt.ylabel('Number of Crimes')연도를 주기로 범죄 수를 시각화한 코드이다.

plt.plot(chicago_df.resample('M').size())
plt.title('Crimes Count Per Month')
plt.xlabel('Months')
plt.ylabel('Number of Crimes')이는 월별로 리샘플링하여 시각화를 한 코드이다.

plt.plot(chicago_df.resample('Q').size())
plt.title('Crimes Count Per Quarter')
plt.xlabel('Quarters')
plt.ylabel('Number of Crimes')이는 분기별로 리샘플링하여 시각화한 코드이다.

Preparing the data
chicago_prophet = chicago_df.resample('M').size().reset_index()월별로 리샘플링하여 설정 인덱스를 제거하고 기본 인덱스로 변경한다.

chicago_prophet.columns = ['Date', 'Crime Count']컬럼을 `Date`, `Crime Count`로 수정한다.
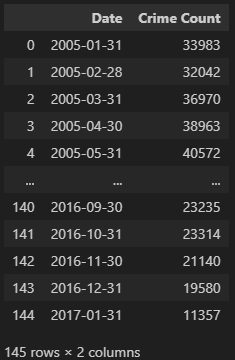
chicago_prophet_df = pd.DataFrame(chicago_prophet)chicago_prophet_df_final = chicago_prophet_df.rename(columns={'Date':'ds', 'Crime Count':'y'})prophet을 사용하려면 Date 컬럼은 `ds`로, 예측값은 `y`로 되어 있어야 한다.
m = Prophet()
m.fit(chicago_prophet_df_final)prophet을 불러 fit 메서드로 예측하려고 하는 데이터프레임을 넣는다.
future = m.make_future_dataframe(periods=720)
forecast = m.predict(future)periods는 일자로 에측할 주기를 입력하면 된다. 720이면 2년 후까지 예측한다.
figure = m.plot(forecast, xlabel='Date', ylabel='Crime Rate')
예측 결과를 시작화하면 이렇게 나온다.
'AI > ML' 카테고리의 다른 글
| 모델 성능평가 척도 (0) | 2025.02.11 |
|---|---|
| Dicision Trees (0) | 2025.02.09 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2025.01.25 |
| 선형회귀와 경사하강법 (0) | 2025.01.24 |