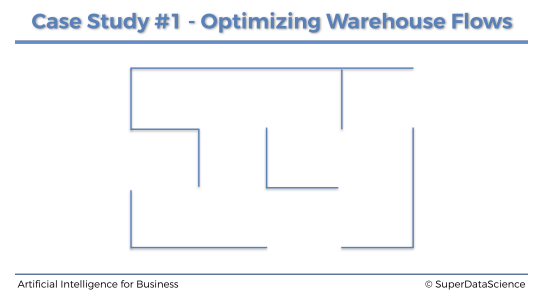
유데미 강의를 보고 실습할 수 있는 자료가 있어 공부하여 코드 분석을 하였다.Problem to solve이런 창고가 있고 창고에는 다른 제품들을 각 12개의 구역에 보관한다.12개의 구역은 각각 A부터 L까지로 나눠져있다고 한다.여기서 각 구역 별로 우선 순위가 정해져 있다.G구역이 최우선 순위이고, 차우선 순위는 K구역이다.Environment to define가장 먼저 해야 할 것은 환경을 정의하는 것이다.그리고 환경을 정의하려면 항상 3가지 요소가 있어야 한다.상태 state 정의행동 action 정의보상 reward 정의Defining the states상태는 A부터 L까지 있으며 문자 그대로 하는 것보다 인덱스로 매핑하는 것은 추후에 정의할 보상 행렬과 Q 행렬을 사용하기 때문이다.상태는 구역..