Stanford 대학의 CS229 머신러닝 강의에서 Lecture 10에 나오는 Dicision Tree에 대해서 보고 정리한 것이다.
Dicision Tree

시간과 위치(위도)가 주어지면 스키를 탈 수 있는지 없는지를 알려주는 분류기가 있다고 가정하자.
위도는 남극의 음극의 90도부터 북극의 양극의 90도까지 있다.
북극은 연초와 연말에 추우니 탈 수 있다, 남극은 반대로 된다. 적도는 항상 더우니 탈 수 없다.
그래서 위와 같은 그래프가 나오게 된다.
의사결정 트리로 무엇을 하고 싶은지 정확히 밝히려면 공간을 개별 영역으로 분할해야 한다.
우리가 의사결정 트리를 사용하는 방법은 기본적으로 Greedy하고, Top-Down, Recursive Partitioning가 있다.

먼저 위도가 30도 보다 큰지에 대해서 분할하면 두 개의 공간이 생긴다. 여기서 재귀적으로 각 공간을 새로운 문제로 취급하여 새로운 질문을 할 수 있다. 예를 드면 3월 보다 적은 달 같은 것으로 말이다.

이러한 재귀적인 질문을 계속해서 반복함으로써 전체 공간을 이렇게 개별 지역으로 나눌 수 있다고 상상할 수 있다.
이를 수학적 표현으로 하자면,

Region이 있고, 이 경우 Region의 부모에 대해 \( R_p \) 라고 하며, 분할 함수인 \( S_p \) 를 찾고 있다.
이 \( S_p \) 함수를 j, t의 함수로 작성할 수 있다. j는 feature 번호이고 t는 사용하는 임계값이다.
x의 j번째 특성이 임계값보다 작은 x집합이 있고, 부모 지역만 분할했기 때문에 \( R_p \) 의 원소인 x가 있다.
그리고 두 번째 집합은 문자 그대로 동일한 것인데, 단지 t보다 크거나 같은 것으로만 구성되어 있다.
따라서 이들 각각을 \( R_1 \) 과 \( R_2 \) 라고 부를 수 있다.

분할을 어떻게 선택하는가?
우리가 하려는 것은 positive와 negative 공간을 나누려고 하는 것이다. 그러니 유용한 건 지역의 손실을 정의하는 것이다.
R에 대한 손실 L를 정의한다. C개의 클래스가 전체적으로 주어졌다고 가정하면, R에서 C클래스에 속하는 예제의 비율을
\( \hat{P}_c \) 로 정의할 수 있다.
전체 영역의 오분류의 손실을 \( L_{\text{misclass}} = 1 - \text{max} \hat{P}_c \) 로 정의할 수 있다.

\( L(R_p) - (L(R_1) + L(R_2)) \) 로 부모 지역에서 위의 집합들을 더한 값을 빼면 된다.

오분류 손실에는 문제가 있다. 그림에서 보는 것처럼 긍정적인 답변 900개, 부정적인 답변 100개가 있다고 하자.
따라서 이것은 100개의 오분류 손실과 같은 것이다.\( R_p \) 에서 \( R_1 \) 와 \( R_2 \) 가 나온다.
\( R_1 \) 에서는 700개의 긍정적 요소와 100개의 부정적 요소가 있다고 가정하고, \( R_2 \) 에서는 200개의 긍정적 요소와 0개의 부정적 요소가 있다고 가정해보자. 오른쪽도 값이 다르지만 이러한 식으로 된다.
이를 맨 오른쪽 수식을 보면 손실을 \( R_1 \) 과 \( R_2 \) 모두 더해보면 100으로 다 똑같고 \( R_p \) 도 100으로 같다.

이러한 문제를 해결하기 위해서 교차 엔트로피 손실(Cross entropy loss)을 정의한다.

크로스 엔트로피 로스는 \( R_1 \) 과 \( R_2 \) 손실의 평균에 해당하는 지점에서 곡선과 직각이 되는 \( R_p \) 와의 차이를 계산하는 것이다. 아래에서 Change in loss로 적혀 있는 부분이 Gain이다. 즉, 부모 노드에서 발생한 로스 보다 자식 노드 2개에서 발생한 로스의 평균이 더 적게 되는 경우다.

Gini 손실이라고 해서 이것도 많이 쓰인다.
Regression Tree

지금까지는 스키를 탈 수 있는지 없는지를 분류하기 위한 의사결정 트리에 대한 것이고, 이제는 그 시간대에 해당 지역에서 예상되는 강설량을 예측하는 회귀를 위한 결정 트리를 이야기 한다.
\( R_m \) 이 있다고 가정하고, \( \hat(y)_m = \frac{\sum_{i=1}^{m} y_i}{\lvert R_m \rvert} \) 은 \( R_m \) 의 모든 지수의 합의 평균을 구하는 식이다.

예측값에서 평균값을 빼는 식으로 손실을 구한다.
범주형 변수

q개의 카테고리가 있는 경우 가능한 분할 수는 \( 2^q \) 로 복잡하고 비효율적이다.
특정 최소 리프 크기에 도달하면 그 리프를 나누는 것을 멈추는 것, 최대 깊이를 설정하고, 최대 노드의 수, 손실을 최소화하고, 검증 데이터에서 잘못 분류된 가지를 제거하는 가지치기가 있다.
Runtime

n은 예제수, f는 피처수, d를 깊이이면 테스트 시간은 \( O(d) \) 이고, 이때 깊이 d는 log2n 보다 작다.
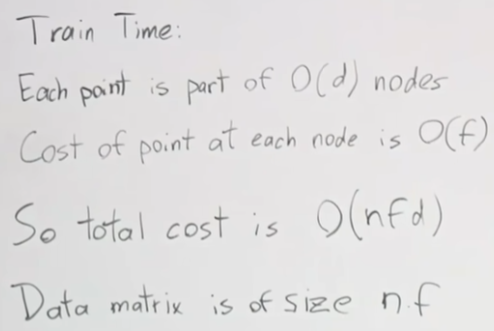
훈련 시간은 각 포인트는 \( O(n) \) 노드에 속한 한 부분이고, 각 노드에서 포인트의 비용은 \( O(f) \) 이다.
깊이 마다, 각 노드에서 피처마다 처리하는 시간이 필요하고 이런 계산을 예제수 만큼해야하니 모두 곱한 \( O(nfd) \)가 훈련 시간이 된다.
장단점
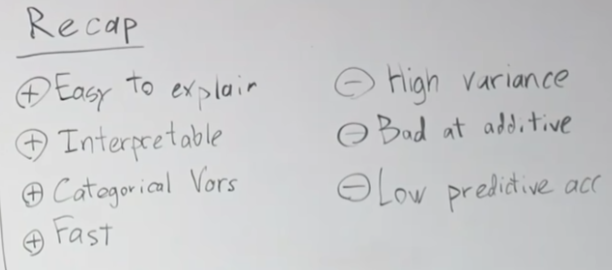
장점으로는 설명하기가 쉽고, 모델을 해석하기 쉽고, 범주형 변수에 유용하며, 빠르다.
단점으로는 높은 분산으로 오버피팅될 수 있고, 첨가 구조에 좋지 않고, 예측 정확도가 낮다.
Ensemble 앙상블
앙상블이 도움이 되는 이유는 뭘까?


확률변수 \( X_i \) 는 P와 상관관계가 있다. 그래서 분산은 \( p \sigma^2 + \frac{1-p}{n} \sigma^2 \) 으로 쓸 수 있다.
상관관계가 완벽히 상관되어 있다면 \( \frac{1-p}{n} \sigma^2 \) , 이 항은 0으로 떨어지고 \( \sigma^2 \) 이 다시 나오는 것을 알게 된다.
Ways to ensemble
앙상블 방법은 여러가지가 있다.

- 다양한 알고리즘을 사용하는 것
- 다양한 훈련 세트를 사용하는 것
- Bagging (서로 다른 훈련 세트를 가지고 있는 것과 비슷한 것을 추정하려는 것) (Random Forest, 의사결정 트리를 위한 배깅의 한 변형)
- Boosting (결정 트리를 위한 부스팅의 변형인 AdaBoost, XGBoost)
Bagging
배깅을 부트스트랩 집계 (Bootstrap Aggregation)이라고도 부른다.

부트스트랩이란 통계에서 추정치의 불확실성을 측정하는 데 일반적으로 사용되는 방법이다.
실제 모집단 P에서 샘플 S를 뽑아서 훈련 세트를 뽑는다.
샘플이 모집단과 같다고 가정하고 모델을 만든다. S에서 다시 샘플을 추출하여 부트스트랩 샘플, Z라는 샘플을 만들고 이것을 훈련에 이용하는 것이다.

훈련 모델을 \( G_m \) 으로 훈련시키고 \( Z_m \) 으로 훈련시킨다.
\( G_m \) 은 개별 모델에 대한 예측의 합계를 전체 모델 수를 나눈 것이다.

부트스트랩은 p를 줄여주고, M이 증가하면 두 번째 항이 감소하게 된다. 그러므로 M이 많을수록 분산은 줄어들게 된다.
대신 랜덤 하위 샘플링으로 인해 편향은 약간 증가할 것이다.
Decision Tree + Bagging

DT는 높은 분산을 가지고 낮은 편향을 가지고 있다.
Bagging은 분산을 낮추기 때문에 좋은 조합이다.
Random Forest

각 분할에서 전체 feature의 일부만 고려한다는 것이다. 예를 들면 첫 번째 구간에서는 위도만, 두 번째 구간에서는 계절만 고려하는 것이다.
Boosting
배깅은 분산을 감소시키고, 부스팅은 반대로 편향을 감소시킨다.
부스팅의 역할은 기본적으로 오분류에 대한 가중치를 증가시키는 것이다.
Adaboost

Decision Tree

아기에게 가족들이 겨울에 찍은 사진을 골라내보라고 해보자.
사진들에서 고려해야 할 것들은 눈이 있는지, 사람인지, 사람의 수는 몇명인지가 중요할 것이다.

이렇게 해서 분리하면 겨울에 찍은 가족사진이 나오게 된다.

의사결정 트리를 만들 때 어떤 특성을 먼저 해야 효과가 좋을지 생각을 해야한다. 우리는 8개의 사진이 있다고 가정하자.

만화 캐릭터인지를 먼저 확인하면 8개 중 4개의 사진이 만화 캐릭터면 걸러지고 남는 사진은 4개이고, 겨울인지를 확인할 때 3장이 여름이면 남는 사진이 5장이고, 사람인지를 확인하면 3장이 걸러지고 5장이 남는다고 생각해보자.
그렇다면 가장 많이 걸러지는 만화 캐릭터를 먼저 분할하는 것이 훨씬 더 좋은 선택이 된다.
그렇게 계속 적게 남는 의사결정에 대해서 선택하면 된다.
References
https://www.youtube.com/watch?v=wr9gUr-eWdA
'AI > ML' 카테고리의 다른 글
| Prophet으로 시카고 범죄율 예측하기 (0) | 2025.02.17 |
|---|---|
| 모델 성능평가 척도 (0) | 2025.02.11 |
| 로지스틱 회귀 (Logistic Regression) (0) | 2025.01.25 |
| 선형회귀와 경사하강법 (0) | 2025.01.24 |