이번 강의에서는 신경망의 뉴론을 삭제하는 이상한 기법인 드롭아웃이 왜 정규화가 될까에 대한 이유를 담고 있는 강의이다.
첫 번째 직관은 더 작고 간단한 신경망을 사용하는 것이 정규화 효과를 주는 것이고, 이번 영상에서는 두 번째 직관에 대해서 설명한다.
드롭아웃이 정규화가 되는 이유
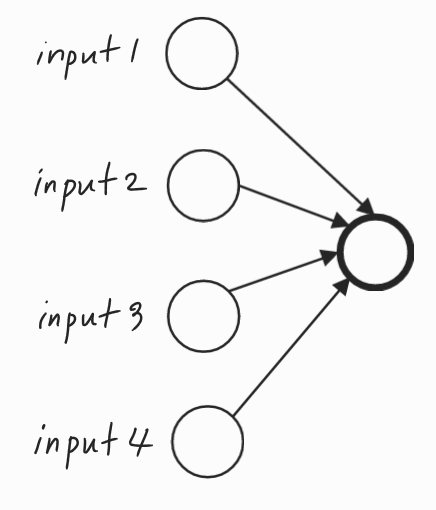
단일 유닛의 관점에서 이 유닛은 입력을 받아 의미있는 출력을 생성해야 한다.

드롭아웃을 통해 입력은 무작위로 삭제될 수 있다. 단일 유닛은 특성이 무작위로 바뀌거나 고유한 입력이 무작위로 바뀔 수 있기 때문에 어떤 특성에도 의존할 수 없다.
따라서 이 특정 입력에 모든 것을 걸 수 없는 상황이다. 즉, 특정 입력에 유난히 큰 가중치를 부여하기가 꺼려지는 상황인 것이다.
그래서 이 네 개의 입력 각각에 가중치를 분산시키는 편이 낫다.
가중치를 분산시킴으로써 L2 정규화에서 봤던 것처럼 가중치의 노름의 제곱값이 줄어들게 된다.
따라서 L2 정규화처럼 과대적합을 막는데 도움이 된다.

이 신경망에서 각 레이어의 뉴런들은 입력 3개, 7, 7, 3, 2, 1로 되어 있다.
우리는 각 층에 해당 유닛이 유지할 확률인 keep_prob 매개변수를 층마다 바꿔야 한다.
첫 번째 층의 가중치 행렬 \( \omega^{[1]} \) 은 (3, 7) 행렬이고, 두 번째 층의 가중치 행렬 \( \omega^{[2]} \) 은 (7, 7), \( \omega^{[3]} \) 은 (7, 3)이다.
\( \omega^{[2]} \) 가 (7, 7)로 가장 많은 매개변수를 갖기 때문에 가장 큰 가중치 행렬이다.
따라서 이 행렬의 과대적합을 줄이기 위해 두 번째 층은 상대적으로 낮은 keep_prob를 가져야 한다. 이를 0.5로 주자.
반면에 과대적합의 우려가 적은 층에서는 0.7 등으로 더 높은 keep_prob를 설정해도 된다.
과대적합 우리가 없는 층은 keep_prob를 1로 설정해도 된다. 1은 모든 유닛을 유지하고 해당 층에서는 드롭아웃을 사용하지 않는다는 의미이다.
그러나 매개변수가 많은 층, 즉 과대적합의 우려가 많은 층은 더 강력한 형태의 드롭아웃을 위해 keep_prob를 작게 설정한다.
L2 정규화에서 다른 층보다 더 많은 정규화가 필요한 층에서 매개변수 \( \lambda \)를 증가시키는 것과 비슷한 것이다.
이론저그올는 입력 층에서도 적용시킬 수 있다. 그러나 이는 실제로 자주 사용하지 않는 것이 좋다. 입력 층에서는 1의 keep_prob가 가장 흔한 값이고, 0.9를 사용하기도 한다.
컴퓨터 비전은 아주 많은 픽셀 값을 모두 사용하기 떄문에 대부분의 경우 데이터가 부족하다. 따라서 컴퓨터 비전에서 거의 대부분 과대적합이 일어나고 드롭아웃이 매우 빈번하게 사용된다.
최근 비전 분야의 연구원들은 거의 항상 기본값으로 드롭아웃을 사용한다. 그러나 여기서 기억해야 할 것은 드롭아웃은 정규화 기법이고 과대적합을 막는데 도움을 준다.
따라서 네트워크가 과대적합의 문제가 생기기 전까지는 드롭아웃을 사용하지 않을 것이다.
드롭아웃의 단점
드롭아웃의 큰 단점은 비용함수 J가 더 이상 잘 정의되지 않는다는 것이다.
모든 반복마다 무작위로 한 뭉치의 노드들을 삭제하게 된다. 경사하강법의 성능을 이중으로 확인한다면 모든 반복에서 잘 정의된 비용함수 J가 하강하는지 확인하는게 어려워진다.
최적화하는 비용함수는 잘 정의되지 않아 계산하기 어려워진다. 따라서 keep_prob를 1로 설정해서 드롭아웃를 하지않고 코드를 실행시켜 비용함수가 단조감소하는지 확인한다.
그리고 코드를 바꾸지 않고 드롭아웃 효과를 다시 줘서 실행시키는 것이 좋다.
References
https://www.youtube.com/watch?v=ARq74QuavAo&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc&index=7
'AI > DL' 카테고리의 다른 글
| Normalizing Inputs (C2W1L09) (0) | 2025.01.30 |
|---|---|
| Other Regularization Methods (C2W1L08) (0) | 2025.01.28 |
| Dropout Regularization (C2W1L06) (0) | 2025.01.28 |
| Why Regularization Reduces Overfitting (C2W1L05) (0) | 2025.01.27 |
| Regularization (C2W1L04) (0) | 2025.01.27 |