유데미 강의를 보고 실습할 수 있는 자료가 있어 공부하여 코드 분석을 하였다.
Problem to solve
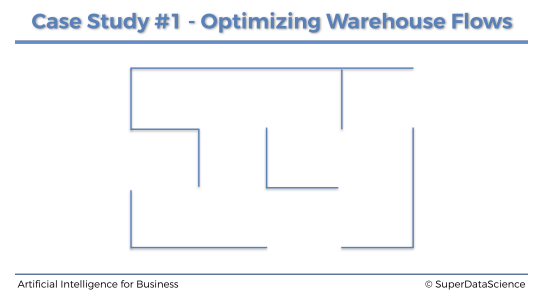
이런 창고가 있고 창고에는 다른 제품들을 각 12개의 구역에 보관한다.
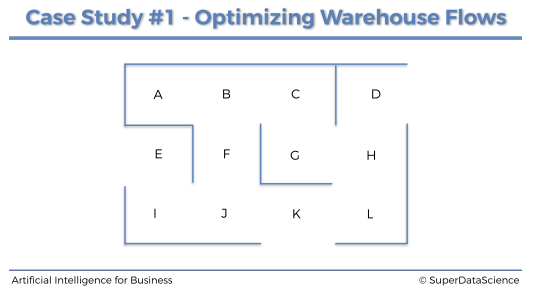
12개의 구역은 각각 A부터 L까지로 나눠져있다고 한다.
여기서 각 구역 별로 우선 순위가 정해져 있다.
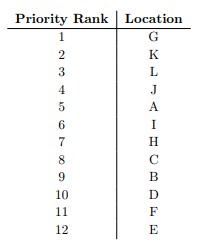
G구역이 최우선 순위이고, 차우선 순위는 K구역이다.
Environment to define
가장 먼저 해야 할 것은 환경을 정의하는 것이다.
그리고 환경을 정의하려면 항상 3가지 요소가 있어야 한다.
- 상태 state 정의
- 행동 action 정의
- 보상 reward 정의
Defining the states
상태는 A부터 L까지 있으며 문자 그대로 하는 것보다 인덱스로 매핑하는 것은 추후에 정의할 보상 행렬과 Q 행렬을 사용하기 때문이다.
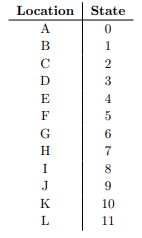
상태는 구역 A부터 L까지를 0부터 11까지로 매핑하면 된다.
Defining the actions
이제 행동을 정의해야 한다. 행동은 현재 위치에서 다음 위치로 이동하기 위한 동작이다.
예를 들어 로봇이 현재 J구역에 있다고 하면 로봇이 갈 수 있는 구역은 F, I, K이다.
그래서 행동은 상태와 같은 인덱스로 가게 된다. 그렇다면 로봇이 J구역, 즉 인덱스 9에서 갈 수 있는 구역은 인덱스 5, 8, 10이다.
따라서 행동은 상태와 마찬가지로 정의하면 된다.
actions = [0,1,2,3,4,5,6,7,8,9,10,11]Defining he rewards
이제 마지막으로 보상을 정의하면 된다.
보상은 상태와 행동에 따라 받게 된다. 즉 로봇이 어디 위치에서 어디로 동작할 수 있는지 없는지에 따라 보상이 달라진다.
여기에서는 로봇이 이동할 수 있는, 할 수 있는 행동에는 1 보상을 주고 할 수 없는 행동에는 0 보상, 아무것도 주지 않도록 한다.
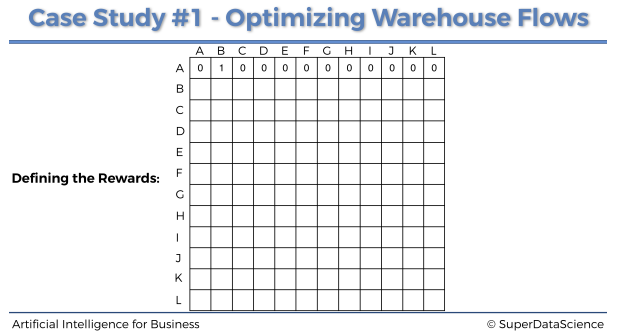
행은 상태를 나타내고, 열은 행동을 나타낸다.
예를 들어 A구역에서는 B구역으로만 이동할 수 있다. 그렇다면 A행 B열에 1 보상을 주고 나머지 칸에는 0을 채워주면 된다. 즉 가능한 이동이면 1을 아니면 0을 채워주면 된다.
이렇게 쭉 채워보면 아래와 같이 채워질 수 있다.
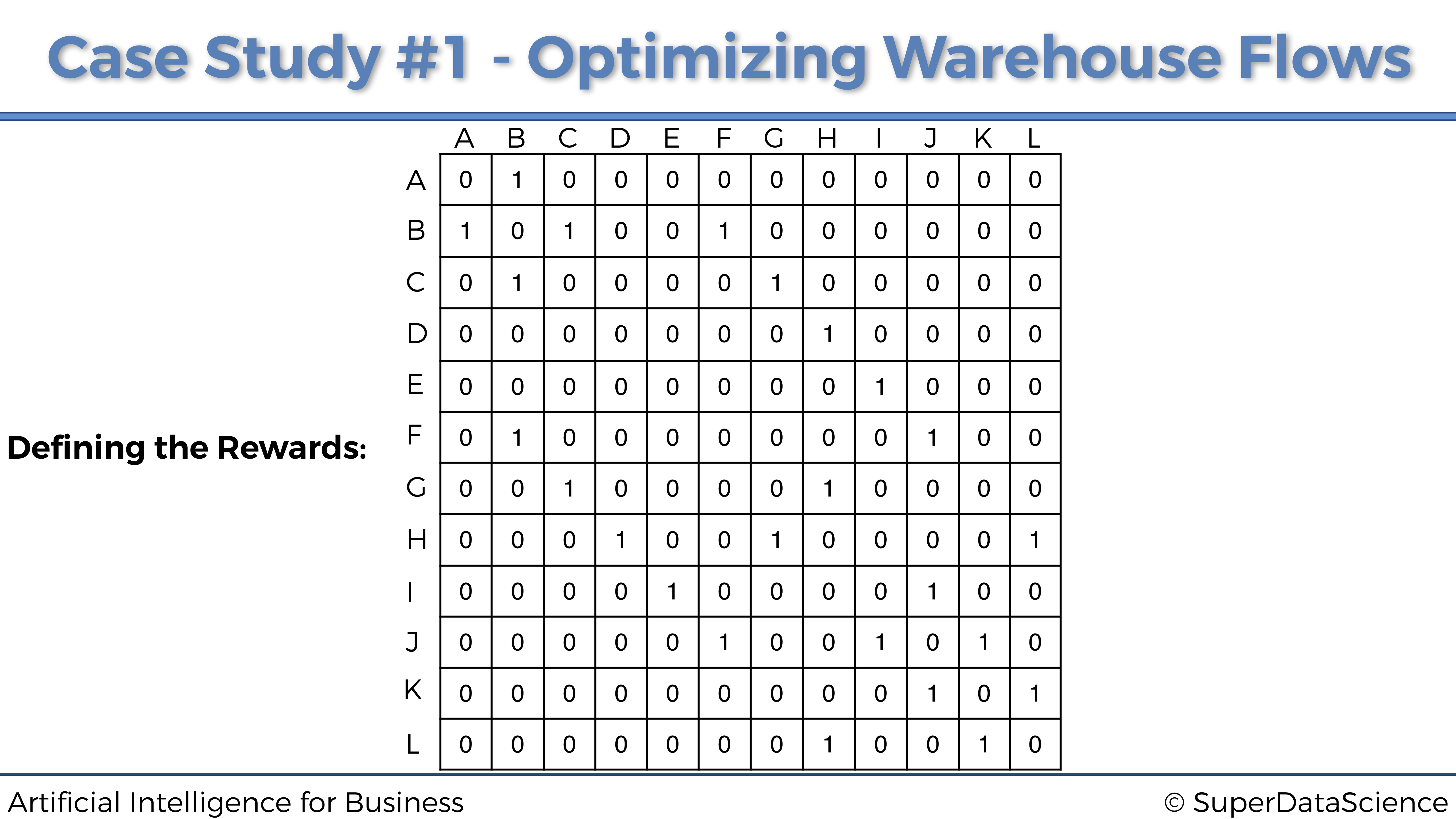
여기서 G구역이 최우선 순위이기 때문에 (G, G)에는 높은 보상을 줘서 최우선으로 갈 수 있도록 해야 한다.
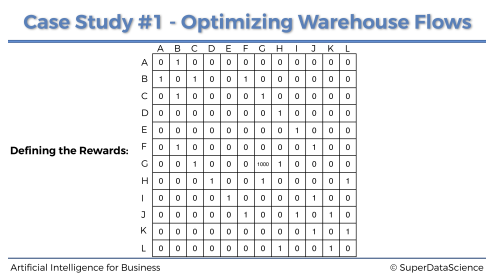
이렇게 보상 행렬을 업데이트하면 된다.
다음은 이제 MDP나 Temporal Difference 시간적 차이가 적용된 벨만 방정식에 대한 것이기 때문에 학습이 되어 있지 않으면 학습하고 오는 것을 추천한다.
여기서는 따로 다루지 않고 이전 포스팅을 남기도록 하겠다.
Q-Learning Imlementation
이제 자질구레한 것은 제외하고 바로 구현을 하기 위해 코드를 하나씩 보자.
import numpy as np먼저 필요한 라이브러리를 import 해주자.
gamma = 0.75
alpha = 0.9이제 중요한 파라미터인 할인계수와 학습률을 미리 선언하여 초기화해두자.
여기서는 할인계수를 0.75, 학습률을 0.9로 설정하였다.
location_to_state = {
'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11
}환경을 설정하기 위해 먼저 해야하는 것은 상태라고 했다.
상태를 먼저 설정해주자.
actions = [0,1,2,3,4,5,6,7,8,9,10,11]다음은 행동을 설정해주자.
R = np.array(
[[0,1,0,0,0,0,0,0,0,0,0,0],
[1,0,1,0,0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0,0,1,0,0],
[0,0,1,0,0,0,1000,1,0,0,0,0],
[0,0,0,1,0,0,1,0,0,0,0,1],
[0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,1,0,0,1,0,1,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,1,0,0,1,0]]
)이전에 했었던 보상행렬에 대해서 선언하고 설정하자.
Q = np.array(np.zeros([12,12]))Q 행렬, Q-Value는 먼저 전부 0으로 초기화된 행렬로 만들어 주면 된다.
for i in range(1000):
current_state = np.random.randint(0,12)
playable_actions = []
for j in range(12):
if R[current_state, j] > 0:
playable_actions.append(j)
next_state = np.random.choice(playable_actions)
TD = R[current_state, next_state] + gamma*Q[next_state, np.argmax(Q[next_state,])] - Q[current_state, next_state]
Q[current_state, next_state] = Q[current_state, next_state] + alpha*TD먼저 Q-Learning 즉 Q 행렬에 값을 채워넣어 로봇이 어느 구역에 갈 행동을 할지 정할 수 있도록 해주자.
코드를 분석해보자면, 큐러닝 프로세스는 1000번 반복한다.
현재 상태를 0부터 12까지 랜덤하게 뽑은 다음 현재 상태에서 이동할 수 있는 상태를 찾기 위해 미리 준비해놨던 보상행열에서 0보다 큰 수를 찾는다.
그리고 다음 상태로 갈 수 있는 행동들 중 하나를 골라서 Q를 업데이트하는 과정이다.
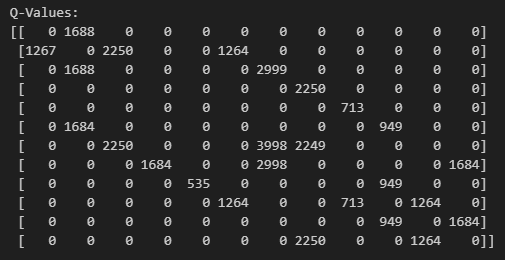
print("Q-Values:")
print(Q.astype(int))업데이트가 끝나고 하면 Q 값을 확인해보자.
state_to_location = {state: location for location, state in location_to_state.items()}현재 우리는 구역을 받아 매핑된 인덱스로 변환하여 큐러닝을 돌렸다.
이제는 학습된 바탕으로 구역을 출력해야 하니 반대로 되어 있는 것이 하나 필요하다. 그래서 stsate_to_location을 준비한다.
def route(starting_location, ending_location):
route = [starting_location]
next_location = starting_location
while (next_location != ending_location):
starting_state = location_to_state[starting_location]
next_state = np.argmax(Q[starting_state,])
next_location = state_to_location[next_state]
route.append(next_location)
starting_location = next_location
return routeroute함수는 시작 구역에서 도착 구역까지의 경로를 배열로 반환해주는 함수이다.
예를 들어 시작 구역을 'E'로 설정했을 때, E구역의 상태 인덱스를 가지고 해당 인덱스의 최대 Q값을 갖는 인덱스를 찾는다. 인덱스는 8이고 이것이 다음 상태가 된다. 다음 상태에 대한 구역은 I구역이고 이를 경로 배열에 집어넣어주고 이를 마지막 구역이 될 때까지 반복해준다.
print('Route:')
route('E', 'G')시작 구역을 E, 종료 구역을 G로 설정하면 아래와 같은 결과를 얻는다.
Route:
Out[1]: [’E’, ’I’, ’J’, ’F’, ’B’, ’C’, ’G’]
Out[2]: [’E’, ’I’, ’J’, ’K’, ’L’, ’H’, ’G’]전체 코드를 여러 번 실행하여 최종 경로를 출력하면 두가지로 가능한 최적 경로를 얻을 수 있다.
Model Improvement 1
# Importing the libraries
import numpy as np
# Setting the parameters gamma and alpha for the Q-Learning
gamma = 0.75
alpha = 0.9
# Defining the states
location_to_state = {
'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11
}
# Defining the actions
actions = [0,1,2,3,4,5,6,7,8,9,10,11]
# Defining the rewards
R = np.array(
[[0,1,0,0,0,0,0,0,0,0,0,0],
[1,0,1,0,0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0,0,1,0,0],
[0,0,1,0,0,0,1,1,0,0,0,0],
[0,0,0,1,0,0,1,0,0,0,0,1],
[0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,1,0,0,1,0,1,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,1,0,0,1,0]]
)
# Making a mapping from the states to the locations
state_to_location = {state: location for location, state in location_to_state.items()}
# Making the final function that will return the route
def route(starting_location, ending_location):
R_new = np.copy(R)
ending_state = location_to_state[ending_location]
R_new[ending_state, ending_state] = 1000
Q = np.array(np.zeros([12,12]))
for i in range(1000):
current_state = np.random.randint(0,12)
playable_actions = []
for j in range(12):
if R_new[current_state, j] > 0:
playable_actions.append(j)
next_state = np.random.choice(playable_actions)
TD = R_new[current_state, next_state] + gamma * Q[next_state, np.argmax(Q[next_state,])] - Q[current_state, next_state]
Q[current_state, next_state] = Q[current_state, next_state] + alpha * TD
route = [starting_location]
next_location = starting_location
while (next_location != ending_location):
starting_state = location_to_state[starting_location]
next_state = np.argmax(Q[starting_state,])
next_location = state_to_location[next_state]
route.append(next_location)
starting_location = next_location
return route
# Printing the final route
print('Route:')
route('E', 'G')이전에는 R 행렬에 최우선 구역의 보상을 일일이 설정해주었다.
여기서 하나의 방법은 경로 함수에서 보상 행렬을 복사한 R_new 행렬에 최우선 구역에 대해 보상을 지정해주는 것이다. 그렇다면 경로 함수를 실행할 때, 입력받는 종료 구역을 최우선 구역으로 하여 보상을 지정해줄 수 있게 된다.
여기서 더 개선시킬 수 있는 부분은 중간 경유지를 설정하는 기능이다.
Model Improvement 2
중간 경유지를 설정하는 방법에는 여러 가지 방법이 있다.
1. Update the rewards
R = np.array(
[[0,1,0,0,0,0,0,0,0,0,0,0],
[1,0,1,0,0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0,0,1,0,0],
[0,0,1,0,0,0,1000,1,0,0,0,0],
[0,0,0,1,0,0,1,0,0,0,0,1],
[0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,1,0,0,1,0,500,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,1,0,0,1,0]]
)경유할 구역 K로 설정한다고 한다면 J구역에서 K로 이어지는 행동에 대해서 보상을 받도록 하면 된다. 보상은 1보다 커야 하며 1000보다 작아야 한다. 그래야 최우선 구역보다 덜 중요하게 로봇이 인식할 수 있으니깐
또 다른 방법은 J구역에서 F구역으로 가는 길목에 - 보상을 줘서 로봇이 가지 못하도록 하는 방법이다.
R = np.array(
[[0,1,0,0,0,0,0,0,0,0,0,0],
[1,0,1,0,0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0,0,1,0,0],
[0,0,1,0,0,0,1000,1,0,0,0,0],
[0,0,0,1,0,0,1,0,0,0,0,1],
[0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,-500,0,0,1,0,1,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,1,0,0,1,0]]
)이렇게 한다면 로봇은 더 많은 보상을 받고 싶기 때문에 -500으로 되어 있는 구역으로 가지를 않을 것이다.
# A Q-Learning Implementation for Process Optimization
# Importing the libraries
import numpy as np
# Setting the parameters gamma and alpha for the Q-Learning
gamma = 0.75
alpha = 0.9
# Defining the states
location_to_state = {'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11}
# Defining the actions
actions = [0,1,2,3,4,5,6,7,8,9,10,11]
# Defining the rewards
R = np.array([[0,1,0,0,0,0,0,0,0,0,0,0],
[1,0,1,0,0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0,0,1,0,0],
[0,0,1,0,0,0,1,1,0,0,0,0],
[0,0,0,1,0,0,1,0,0,0,0,1],
[0,0,0,0,1,0,0,0,0,1,0,0],
[0,0,0,0,0,1,0,0,1,0,1,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,1,0,0,1,0]])
# Making a mapping from the states to the locations
state_to_location = {state: location for location, state in location_to_state.items()}
# Making a function that returns the shortest route from a starting to ending location
def route(starting_location, ending_location):
R_new = np.copy(R)
ending_state = location_to_state[ending_location]
R_new[ending_state, ending_state] = 1000
Q = np.array(np.zeros([12,12]))
for i in range(1000):
current_state = np.random.randint(0,12)
playable_actions = []
for j in range(12):
if R_new[current_state, j] > 0:
playable_actions.append(j)
next_state = np.random.choice(playable_actions)
TD = R_new[current_state, next_state] + gamma * Q[next_state, np.argmax(Q[next_state,])] - Q[current_state, next_state]
Q[current_state, next_state] = Q[current_state, next_state] + alpha * TD
route = [starting_location]
next_location = starting_location
while (next_location != ending_location):
starting_state = location_to_state[starting_location]
next_state = np.argmax(Q[starting_state,])
next_location = state_to_location[next_state]
route.append(next_location)
starting_location = next_location
return route
# Making the final function that returns the optimal route
def best_route(starting_location, intermediary_location, ending_location):
return route(starting_location, intermediary_location) + route(intermediary_location, ending_location)[1:]
# Printing the final route
print('Route:')
print(best_route('E', 'K', 'G'))위의 두 아이디어는 수동으로 구현하는 방법으로 쉽지만 귀찮음이 있다.
자동으로 중간 경유지를 지날 수 있도록 하기 위해 best_route라는 함수를 만들었다.
이는 route 함수 두 개를 사용해 하나는 시작 구역부터 중간 구역까지의 경로와 중간 구역부터 종료 구역까지의 경로를 합쳐 반환해주는 것이다. 그렇게 하면 E부터 G까지 가야하는데 K를 무조건 경유하여 갈 수 있게 된다.
'AI > RL' 카테고리의 다른 글
| 시간적 차이 Temporal Difference (0) | 2025.02.18 |
|---|---|
| 상태가치함수와 행동가치함수(Q함수) (0) | 2025.02.18 |
| [RL] Living Penalty (1) | 2025.02.18 |
| Plan과 Policy (1) | 2025.02.18 |
| 마르코프 의사결정 과정(MDP) (0) | 2025.02.17 |