이전의 포스팅을 보면 전부 V(s)를 구하는 것으로 되어 있다.
2025.02.17 - [AI/RL] - 마르코프 의사결정 과정(MDP)
마르코프 의사결정 과정(MDP)
마르코프 의사결정 과정(Markov Dicision Process, MDP)은 순차적인 의사결정 문제를 수학적으로 모델링하는 방법이다.이는 강화학습에서 핵심 개념으로 사용되며, 에이전트가 환경과 상호 작용하면서
hu-bris.tistory.com
지금까지는 특정 상태가 되었을 때의 가치에 대해 공부했다.
이제는 Q를 활용하여 Q-Learning에 더 가까워져보려고 한다.
Q가 무엇인가?
큐러닝에 Q가 무엇일까?
지금까지 각 상태의 가치를 보고 정책을 정한다고 하면, 이제는 각 행동의 가치를 보는 것이다.
이제 V는 상태 가치를 나타내니 쓰지 않고 Q를 쓸 것이다.
Q는 쿼라라는 단어에서 왔다고도 하고, 퀄리티에서 왔다고도 한다. 유래를 알 수는 없지만 Q로 쓰는 것이 유명해져서 이제는 그냥 Q-Learning이라고 한다.
행동 가치 함수, 각 행동에 따라 행동의 정량화된 가치를 알려주는 공식이다. 이를 Q라고 하며 이제 Q의 공식을 알아 보려고 한다.
상태 가치 함수

이전에 공부했던 수식이다.
현재 상태의 가치는 현재 상태를 행동했을 때 얻는 보상과 새로운 상태의 기댓값과 할인 계수를 곱한 값을 더하면 된다.
새로운 상태로 가기 위한 옵션 위, 아래, 왼, 오른 쪽이 있으니 어떻게 될지 모르니 확률이 있으니 기댓값이 있는 것이다.
행동 가치 함수
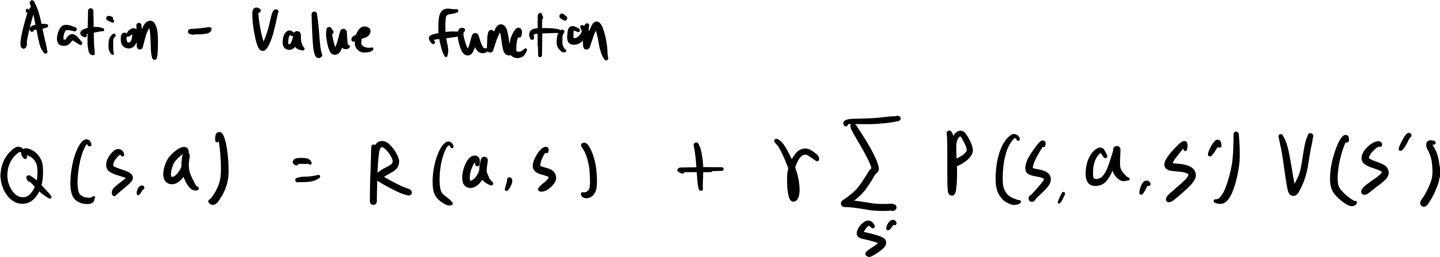
Q를 이제 정의해보자.
에이전트가 현재 상태에서 위로 간다고 하면 Q 값은 어떻게 될까?
먼저 위로 가는 행동을 수행하면 어떤 결과가 나오는지 봐야 한다.
가장 먼저 얻는 것은 보상 R(a, s)이 될 것이다.
다음은 위로 가려고 하면 에이전트가 80% 확률로 위로 가겠지만, 남은 20% 확률로 왼쪽이나 오른쪽으로 갈 수도 있다.
어디로 이동하든 상관없이 새로운 상태에 대해 정량화된 측정 기준이 있다. 그게 상태 가치이다.
그래서 이전과 같이 할인계수와 함께 뒤의 항이 만들어지게 된다.
상태 가치 함수와 행동 가치 함수의 관계
위의 상태 가치 함수와 행동 가치 함수를 잘 보면 뭔가 눈치챘을만 한 것이 있을 것이다.

상태 가치함수의 괄호부분이 Q와 같다는 것이다.
그렇다면 이는 사진과 같이 정의할 수 있다.
$$ V(s) = max_a\{Q(s, a)\} $$
즉 상태의 가치는 각 행동(위, 아래, 왼, 오른)을 수행했을 때의 결과의 최댓값을 보는 것이다.
이제 여기서 V를 없앨 것이다.

V를 Q로 대체하려면 다음 상태의 가치 V를 위의 상태 가치 함수를 대입해보면 된다.
위에서 V(s)는 모든 Q(s, a)의 최댓값이라고 했으니 여기에 그걸로 대체하는 것이다.

그렇다면 이렇게 새로운 행동의 최댓값이 나오게 된다.
정리하자면 행동에 대한 가치 값은 현재 행동을 한 보상과 새로운 상태의 기댓값과 새로운 행동의 가치값과 할인계수가 곱해진 값을 더한 것이 현재 행동에 대한 가치 값이 나오게 된다.
이 Q를 에이전트가 사용하는 것이 Q-Learning이라고 한다.
상태를 보는 것이 아니라, 가능한 행동을 보고 행동의 Q값에 따라서 어떤 행동을 수행할지 결정하게 된다.
이 상태에서 Q값의 최댓값만 보는 것이다.
다양한 상태를 비교해 보고 현재 가능한 행동도 비교해 보고 그중 최적의 행동을 찾아내서 수행되는 과정을 반복하는 것이다.
'AI > RL' 카테고리의 다른 글
| 자율 창고 로봇 프로세스 최적화를 위한 Q-Learning 구현 (1) | 2025.02.20 |
|---|---|
| 시간적 차이 Temporal Difference (0) | 2025.02.18 |
| [RL] Living Penalty (1) | 2025.02.18 |
| Plan과 Policy (1) | 2025.02.18 |
| 마르코프 의사결정 과정(MDP) (0) | 2025.02.17 |