C4W3L01 Object Localization
최근 컴퓨터 비전 분야에서는 단순한 이미지 분류를 넘어, 이미지 내 물체의 위치까지 정확히 파악하는 물체 감지(Object Detection) 기술이 큰 주목을 받고 있습니다. 이번 포스팅에서는 물체 감지의 핵심 개념인 로컬리제이션 분류(Localization Classification)와, 이를 구현하기 위한 신경망 설계의 기본 아이디어를 살펴보겠습니다.
물체 감지와 로컬리제이션 분류란?
일반적인 이미지 분류 문제에서는 신경망이 이미지를 보고 "이것은 자동차다"와 같이 한 가지 레이블을 예측한다. 그러나 물체 감지 문제에서는 단순히 무엇이 있는지를 분류하는 것을 넘어,
- 물체의 존재 여부,
- 물체의 종류 (예: 보행자, 자동차, 오토바이 등),
- 그리고 물체의 위치를 함께 예측해야 한다.
즉, 단순 분류 문제와 달리 물체 감지에서는 이미지 내 여러 개의 물체를 대상으로 각각의 위치(경계 상자)를 출력해야 한다.
로컬리제이션 분류의 역할
물체 감지에서 가장 먼저 다루어야 할 것은 로컬리제이션(Localization) 문제이다.
- 로컬리제이션 분류는 단순히 이미지에 포함된 물체의 종류를 판단하는 것이 아니라, 해당 물체가 이미지 내 어디에 위치하는지 (예: 경계 상자)도 결정한다.
- 예를 들어, 자율주행 시스템에서는 "자동차"라는 레이블뿐만 아니라, 그 자동차의 위치를 나타내는 경계 상자(보통 빨간 직사각형으로 표시)를 함께 제공해야 한다.
또한, 물체의 존재 여부를 나타내는 확률 \( p_c \)와, 물체의 종류를 분류하기 위한 추가 변수들(예: \( c_1, c_2, c_3 \) 등)이 사용된다.
예를 들어, 만약 자동차가 이미지에 존재한다면 \( p_c = 1 \)이 되고, 해당하는 분류 변수(예: \( c_2 \))가 1로 설정된다.
반대로, 물체가 없는 경우 \( p_c = 0 \)이며, 경계 상자와 분류 관련 나머지 요소들은 무관한 값(예: 물음표)으로 처리된다.
목표 레이블과 손실 함수
훈련 과정에서, 지도학습(Supervised Learning)을 통해 이미지에 대한 목표 레이블 \( y \)를 정의한다.
이때 \( y \)는 다음과 같은 구성 요소로 이루어진다
- \( p_c \): 물체의 존재 여부 (예: 1이면 물체 있음, 0이면 물체 없음)
- \( b_x, ; b_y, ; b_h, ; b_w \): 물체가 존재할 경우 경계 상자의 좌표 및 크기
- \( c_1, ; c_2, ; c_3 \): 물체의 종류를 나타내는 분류 정보 (예: 보행자, 자동차, 오토바이 등)
훈련 중에 신경망은 이와 같이 구성된 \( y \)와 예측값 \( \hat{y} \) 사이의 차이를 최소화하도록 학습된다.
손실 함수(loss function)로는 제곱 오차(Mean Squared Error, MSE)나 로그 우도 손실(Log-Likelihood Loss)을 사용할 수 있다.
예를 들어, 물체가 존재하는 경우 손실은 다음과 같이 계산된다
$$ \text{Loss} = (\hat{p}_c - p_c)^2 + (\hat{b}_x - b_x)^2 + (\hat{b}_y - b_y)^2 + (\hat{b}_h - b_h)^2 + (\hat{b}_w - b_w)^2 + \sum_{i} (\hat{c}_i - c_i)^2 $$
물체 감지 신경망의 중요성
물체 감지 기술은 자율주행, 보안 시스템, 의료 영상 분석 등 다양한 응용 분야에서 매우 중요하다.
- 자율주행 자동차의 경우, 단순히 도로 위의 자동차만이 아니라 보행자, 오토바이 등 다양한 객체를 동시에 감지해야 한다.
- 이미지 내에서 여러 객체를 동시에 감지하는 능력은 신경망 설계와 학습 데이터 구성에 따라 크게 달라질 수 있다.
C4W3L02 Landmark Detection
이전 강의에서는 신경망이 사물의 경계 상자를 나타내는 4개의 출력을 어떻게 얻는지 살펴보았습니다 ( \( b_x, ; b_y, ; b_h, ; b_w \) ). 이번 강의에서는 특징점 검출이라는 개념을 소개하고, 이를 통해 얼굴 인식 시스템을 설계하는 방법을 설명합니다.
특징점 검출 (Landmark Detection)
특징점은 이미지에서 중요한 지점을 나타내는 좌표 (x, y)이다. 신경망은 이러한 특징점의 위치를 인식하도록 학습될 수 있다.
예시: 얼굴 인식 시스템
얼굴 인식 시스템을 설계한다고 가정해 보자. 우리는 알고리즘이 눈꼬리의 위치를 찾아내기를 원한다. 눈꼬리 위치는 x, y 좌표로 표현되므로, 신경망은 마지막 계층에서 두 개의 출력을 갖는다.
lx, ly (눈꼬리 위치 좌표)
만약 두 눈의 네 개의 눈꼬리를 모두 표현하고 싶다면 어떻게 해야 할까? 왼쪽부터 오른쪽으로 눈꼬리를 1번, 2번, 3번, 4번이라고 부른다면, 신경망은 다음과 같이 8개의 출력을 갖도록 수정할 수 있다.
l1x, l1y (1번 눈꼬리)
l2x, l2y (2번 눈꼬리)
...
l4x, l4y (4번 눈꼬리)다양한 특징점 검출
단순히 눈꼬리뿐만 아니라, 눈 위, 입술, 코 윤곽선 등 다양한 특징점을 검출할 수 있다. 이러한 특징점들을 활용하면 얼굴 모양을 추출하여 웃거나 찡그리는 표정을 인식할 수 있다.
얼굴에 64개의 특징점을 지정한다고 가정하면, 턱 윤곽선을 따라 특징점을 추출할 수 있다.
이미지 처리 과정
- 입력: 사람 얼굴 이미지를 입력으로 받는다.
- 합성곱 신경망: 이미지는 합성곱 신경망을 통과하며 특징을 추출한다.
- 출력
- 얼굴 유무 (0 또는 1)
- 64개의 특징점 좌표 (l1x, l1y, ..., l64x, l64y)
스냅챗 필터
특징점 검출 기술은 스냅챗과 같은 엔터테인먼트 앱에서 증강 현실 필터를 구현하는 데 사용된다. 얼굴 위에 왕관을 그리거나 다양한 특수 효과를 적용하는 것이 가능하다.
훈련 데이터
신경망을 훈련하려면 레이블링된 훈련 데이터 세트가 필요하다. 각 이미지에 대해 특징점의 정확한 위치를 수동으로 표시하거나, 사람을 고용하여 충분히 큰 데이터 세트를 구축해야 한다.
C4W3L03 Object Detection
이전 강의에서는 물체 로컬리제이션과 특징점 검출에 대해 배우고, 이어서 물체 인식 알고리즘을 설계하는 방법을 학습했습니다. 이번 강의에서는 합성곱 신경망(Convolutional Neural Network, CNN)을 사용하여 물체 인식을 구현하는 방법을 배우고, 슬라이딩 윈도우(Sliding Window) 검출 알고리즘을 사용하는 방법을 설명합니다.
훈련 데이터 세트 준비
가장 먼저 해야 할 일은 레이블링된 훈련 데이터 세트를 준비하는 것이다. 이미지 x와 레이블 y로 구성된 데이터 세트에서, 자동차에 근접하게 잘린 샘플을 사용한다. 긍정 샘플은 자동차 이미지를 포함하고, 부정 샘플은 자동차가 아닌 이미지를 포함한다.
합성곱 신경망 훈련
준비된 훈련 데이터 세트를 사용하여 합성곱 신경망을 훈련한다. 입력으로 잘린 이미지를 사용하고, 출력 y는 이미지가 자동차인지 아닌지에 따라 0 또는 1 값을 갖는다.
슬라이딩 윈도우 검출
훈련된 합성곱 신경망을 사용하여 슬라이딩 윈도우 검출을 수행한다.
- 윈도우 크기 선택: 특정 크기의 윈도우를 선택한다.
- 이미지 슬라이딩: 선택한 윈도우를 사용하여 이미지를 왼쪽에서 오른쪽, 위에서 아래로 슬라이딩한다.
- 합성곱 신경망 입력: 각 윈도우에 해당하는 이미지를 합성곱 신경망에 입력한다.
- 예측값 계산: 합성곱 신경망은 각 윈도우에 대해 예측값을 계산한다.
- 반복: 윈도우 크기를 변경하며 위 과정을 반복한다.
슬라이딩 윈도우 검출의 장단점
- 장점: 비교적 간단하게 구현할 수 있다.
- 단점: 계산 비용이 매우 높다. 이미지의 모든 영역을 잘라내어 합성곱 신경망에 통과시켜야 하므로 많은 시간이 소요된다.
계산 비용 문제 해결
슬라이딩 윈도우 검출은 계산 비용이 매우 높다는 단점이 있다. 하지만 다행히도 이 문제를 해결할 방법이 있다. 다음 강의에서는 합성곱 연산을 사용하여 슬라이딩 윈도우 물체 인식기를 훨씬 효율적으로 구현하는 방법을 배우게 된다.
C4W3L04 Convolutional Implementation Sliding Windows
지난 강의에서는 합성곱 신경망(CNN) 기반의 슬라이딩 윈도우(Sliding Window) 물체 검출 알고리즘을 배웠지만, 계산 속도가 느리다는 단점이 있었습니다. 이번 강의에서는 합성곱 연산을 활용하여 슬라이딩 윈도우 알고리즘을 효율적으로 구현하는 방법을 알아봅니다.
완전 연결 층을 합성곱 층으로 변환
슬라이딩 윈도우의 합성곱 구현을 위해, 먼저 신경망의 완전 연결 층(Fully Connected Layers)을 합성곱 층(Convolutional Layers)으로 변환하는 방법을 살펴보자.
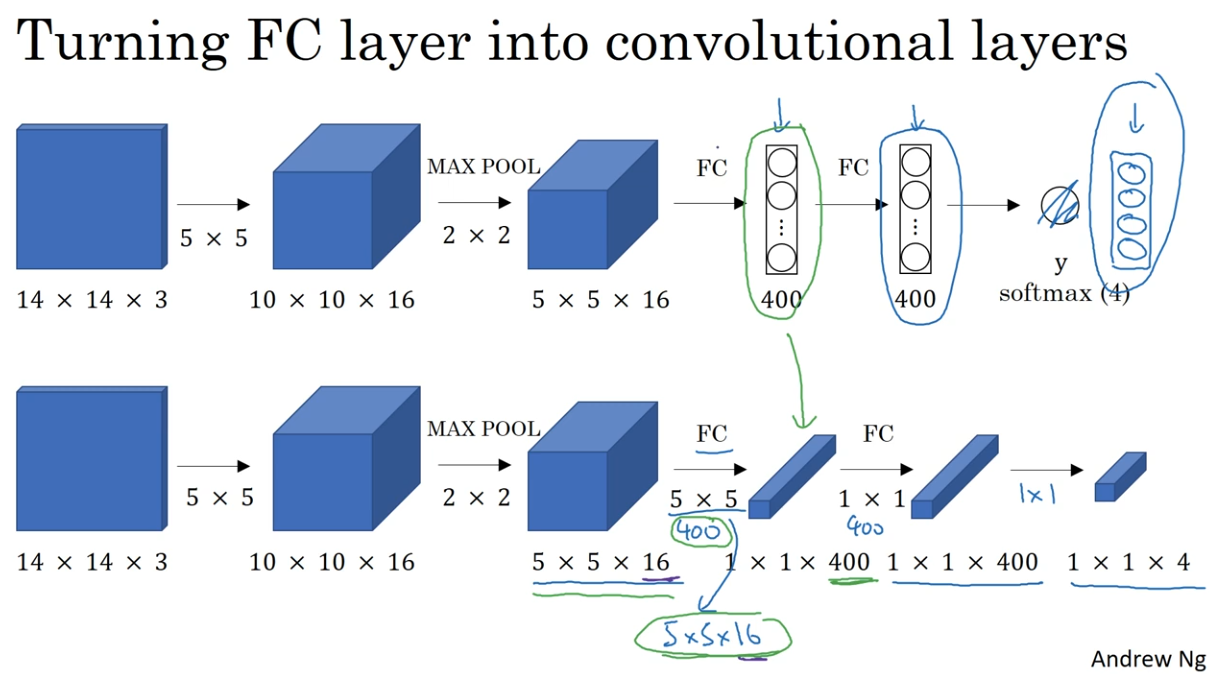
- 입력 이미지: 14x14x3 크기의 이미지를 입력으로 사용한다 (설명 편의를 위해 작은 크기를 사용).
- 합성곱 층: 16개의 5x5 필터를 사용하여 10x10x16 크기로 변환한다.
- 최대 풀링: 2x2 최대 풀링을 적용하여 5x5x16 크기로 줄인다.
- 완전 연결 층: 400개의 유닛을 가진 완전 연결 층을 생성한다.
- 완전 연결 층: 또 다른 완전 연결 층을 추가한다.
- 출력 층: 소프트맥스(Softmax) 유닛을 사용하여 4가지 분류 (보행자, 자동차, 오토바이, 배경) 중 하나를 출력한다.
완전 연결 층을 합성곱 층으로 변환하는 과정
- 초기 층: 합성곱 신경망의 초기 층은 동일하게 유지한다.
- 5x5 필터: 400개의 5x5 필터를 사용하여 완전 연결 층을 대체한다.
- 1x1 합성곱: 1x1 합성곱 필터를 사용하여 완전 연결 층을 추가로 대체한다.
- 출력 층: 1x1 필터를 사용하여 소프트맥스 활성 출력을 생성한다.
슬라이딩 윈도우의 합성곱 구현
다음으로, 위에서 배운 완전 연결 층의 합성곱 층 변환 방법을 활용하여 슬라이딩 윈도우를 합성곱으로 구현하는 방법을 알아보자.
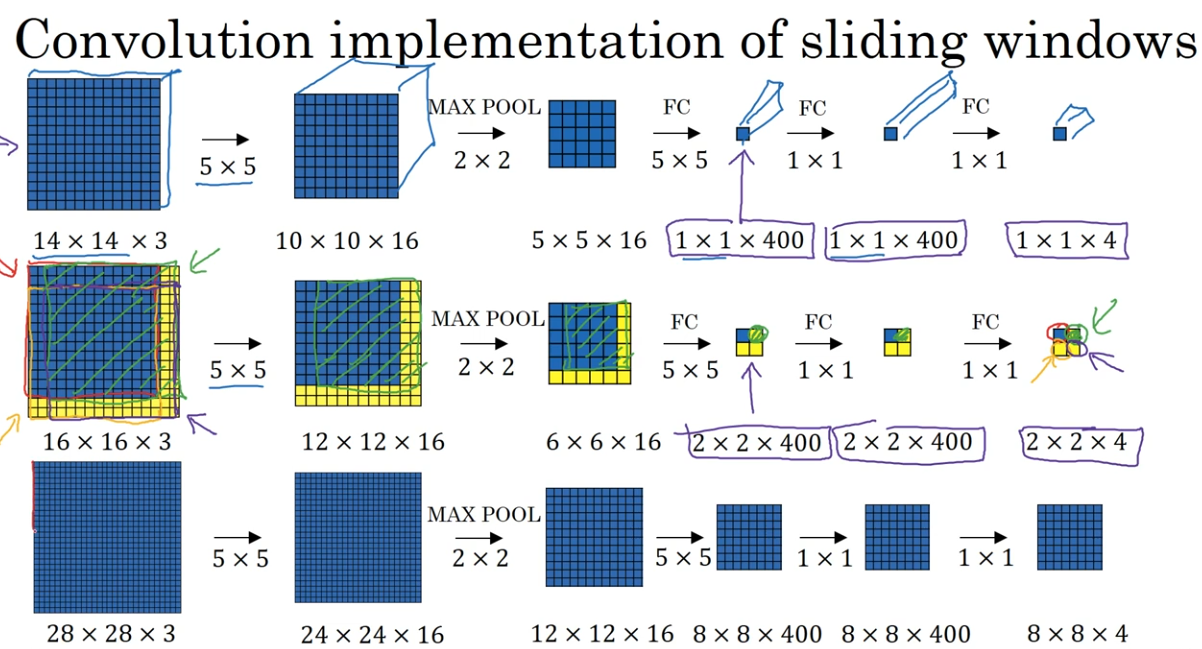
- 입력 이미지: 16x16x3 크기의 이미지를 입력으로 사용합니다 (테스트 이미지).
- 슬라이딩 윈도우: 14x14 크기의 윈도우를 사용하여 이미지를 슬라이딩한다.
- 합성곱 연산: 각 윈도우에 대해 합성곱 연산을 수행한다.
- 출력: 2x2x4 크기의 출력을 얻는다.
슬라이딩 윈도우의 문제점
각 윈도우마다 독립적인 계산을 수행하므로 계산량이 많다.
합성곱을 이용한 슬라이딩 윈도우의 장점
- 윈도우 간의 계산을 공유하여 계산량을 줄인다.
- 전체 이미지를 한 번에 처리하여 효율적인 계산이 가능하다.
더 큰 샘플에 대한 슬라이딩 윈도우
28x28x3 크기의 이미지에 대해 슬라이딩 윈도우를 수행하는 경우에도 동일한 방법을 적용할 수 있다. 14x14 윈도우를 사용하여 이미지를 슬라이딩하고, 합성곱 연산을 통해 8x8x4 크기의 출력을 얻는다.
C4W3L06 Intersection Over Union
물체 감지 알고리즘의 성능을 평가하는 것은 매우 중요한 과정입니다. 이번 영상에서는 IoU (Intersection over Union, 합집합 위의 교집합)라는 함수를 사용하여 물체 감지 알고리즘의 성능을 평가하는 방법을 배웁니다. IoU는 물체 감지 알고리즘의 평가뿐만 아니라, 다음 영상에서 다룰 비-최댓값 억제 (Non-Maximum Suppression)와 같은 알고리즘 개선에도 활용됩니다.
IoU (합집합 위의 교집합) 란?
IoU는 두 경계 상자의 겹침 정도를 측정하는 함수이다.
- 참 값 경계 상자 (Ground Truth Bounding Box): 실제 물체의 위치를 나타내는 경계 상자
- 예측 값 경계 상자 (Predicted Bounding Box): 알고리즘이 예측한 물체의 위치를 나타내는 경계 상자
IoU는 다음 공식으로 계산된다.
IoU = (교집합 영역) / (합집합 영역)- 교집합 영역: 두 경계 상자가 겹치는 영역
- 합집합 영역: 두 경계 상자를 모두 포함하는 영역
IoU를 사용한 물체 감지 알고리즘 평가
일반적으로 IoU가 0.5보다 크면 물체 감지 알고리즘이 물체를 올바르게 탐지했다고 판단한다. 즉, 예측 값 경계 상자가 참 값 경계 상자와 충분히 겹쳐져 있으면 정확한 탐지로 간주하는 것이다.
- IoU가 1에 가까울수록 경계 상자가 더 정확하다.
- IoU 임계값은 0.5 외에 0.6, 0.7 등 다른 값을 사용할 수도 있다 (더 엄격한 기준).
IoU의 활용
IoU는 다음과 같은 용도로 활용된다.
- 물체 감지 알고리즘 평가: 알고리즘의 정확도를 측정하는 지표로 사용된다.
- 비-최댓값 억제 (NMS): 여러 개의 예측 값 경계 상자 중에서 가장 정확한 상자를 선택하는 데 사용된다.
C4W3L07 Nonmax Suppression
이전 강의에서 배운 물체 감지 알고리즘은 동일한 물체를 여러 번 감지하는 문제가 발생할 수 있습니다. 비-최댓값 억제 (Non-Maximum Suppression, NMS)는 이러한 문제를 해결하고 각 물체를 한 번씩만 감지하도록 하는 기술입니다.
문제점: 중복 감지
물체 감지 알고리즘은 이미지 내의 모든 격자 셀에 대해 물체 분류 및 지역화 작업을 수행한다. 이 과정에서 하나의 물체에 대해 여러 개의 격자 셀이 물체를 포함한다고 판단할 수 있다. 특히, 물체의 중심이 여러 개의 격자 셀에 걸쳐 있을 경우 이러한 문제가 더욱 심각해진다.
해결책: 비-최댓값 억제 (NMS)
NMS는 다음과 같은 단계를 거쳐 중복 감지 문제를 해결한다.

- 확률 기반 정렬: 각 감지 결과의 확률 (Pc)을 기준으로 내림차순으로 정렬한다.
- 최대 확률 선택: 가장 높은 확률을 가진 감지 결과를 선택하고, 해당 결과를 최종 감지 결과로 확정한다.
- IOU 계산 및 억제: 선택된 감지 결과와 IoU (Intersection over Union, 합집합 위의 교집합)가 높은 나머지 감지 결과들을 억제한다. IoU는 두 경계 상자의 겹침 정도를 측정하는 지표이다.
- 반복: 2단계와 3단계를 반복하여 모든 감지 결과를 처리한다.
NMS 알고리즘 상세 과정
- 입력: 19x19 격자에서 도출된 19x19x8 크기의 결과 (각 셀마다 물체 유무 확률 및 경계 상자 정보 포함).
- 확률 임계값 설정: Pc가 특정 임계값 (예: 0.6) 이하인 경계 상자들을 제거한다.
- 반복
- 남은 경계 상자 중 가장 높은 Pc를 가진 것을 선택하고 최종 감지 결과로 확정한다.
- 선택된 경계 상자와 IoU가 높은 (즉, 많이 겹치는) 나머지 경계 상자들을 제거한다.
- 남은 경계 상자가 없을 때까지 반복한다.
다중 물체 클래스
만약 보행자, 자동차, 오토바이 등 여러 개의 물체 클래스를 검출해야 한다면, 각 클래스에 대해 독립적으로 NMS를 수행해야 한다.
C4W3L08 Anchor Boxes
이전 강의에서 배운 물체 감지 알고리즘은 각 격자 셀이 오직 하나의 물체만 감지할 수 있다는 제한점이 있습니다. 만약 하나의 격자 셀 안에 여러 개의 물체가 존재한다면 어떻게 해야 할까요? 앵커 박스 (Anchor Boxes)는 이러한 문제를 해결하고 하나의 격자 셀에서 여러 개의 물체를 감지할 수 있도록 도와주는 기술입니다.
문제점: 하나의 격자 셀, 하나의 물체
기존의 물체 감지 알고리즘은 각 격자 셀마다 하나의 물체만 감지할 수 있다. 따라서 만약 여러 개의 물체가 같은 격자 셀 안에 위치한다면, 알고리즘은 이들을 모두 감지하지 못하거나, 혹은 하나의 물체만 잘못 감지할 수 있다.
해결책: 앵커 박스
앵커 박스는 미리 정의된 다양한 모양의 경계 상자이다. 앵커 박스를 사용하면 하나의 격자 셀에서 여러 개의 물체를 감지할 수 있다.
앵커 박스 작동 방식
- 앵커 박스 정의: 다양한 모양의 앵커 박스 (예: 길쭉한 모양, 넓적한 모양)를 미리 정의한다.
- 각 물체 매칭: 각 물체에 대해 가장 높은 IoU (Intersection over Union, 합집합 위의 교집합)를 가지는 앵커 박스를 찾는다.
- 격자 셀 및 앵커 박스 매칭: 각 물체를 해당 물체의 중심점이 위치한 격자 셀과, 가장 높은 IoU를 가지는 앵커 박스에 매칭한다.
- 타겟 레이블 부호화: 각 격자 셀에서, 해당 셀에 매칭된 물체들의 정보 (클래스, 경계 상자 파라미터)를 앵커 박스에 따라 부호화한다.
앵커 박스 알고리즘 상세 과정
- 훈련 세트 준비: 훈련 세트 이미지 속 각 물체는 중심점이 위치한 격자 셀에 할당된다.
- 앵커 박스 정의: 여러 개의 앵커 박스 모양을 정의한다.
- 물체-앵커 박스 매칭: 각 물체에 대해 가장 높은 IoU를 가지는 앵커 박스를 찾는다.
- 물체-격자 셀-앵커 박스 매칭: 각 물체를 중심점이 위치한 격자 셀과, 가장 높은 IoU를 가지는 앵커 박스에 매칭한다.
- 타겟 레이블 부호화: 각 격자 셀에서, 매칭된 물체들의 정보를 앵커 박스에 따라 부호화한다.
앵커 박스 예시
3x3 격자 셀을 가진 이미지에서, 보행자와 자동차의 중심점이 거의 같은 위치에 있다고 가정해 보자. 이 경우, 보행자는 길쭉한 모양의 앵커 박스에, 자동차는 넓적한 모양의 앵커 박스에 매칭될 수 있다.
앵커 박스 선택 방법
- 수동 선택: 감지하려는 물체의 다양한 모양을 고려하여 5~10개의 앵커 박스를 수동으로 선택한다.
- K-평균 알고리즘: 데이터 세트에서 물체 모양을 클러스터링하여 앵커 박스 세트를 자동으로 선택한다.
앵커 박스의 장점
- 다양한 모양의 물체 감지: 앵커 박스를 통해 다양한 모양의 물체를 효과적으로 감지할 수 있다.
- 학습 알고리즘 특화: 특정 모양의 물체 (예: 길쭉한 보행자, 넓적한 자동차) 감지에 특화된 학습 알고리즘을 개발할 수 있다.
C4W3L09 YOLO Algorithm
이전 강의들에서 물체 감지의 다양한 요소들을 배우셨습니다. 이번 영상에서는 이 요소들을 통합하여 YOLO (You Only Look Once) 물체 감지 알고리즘을 완성하는 방법을 설명합니다.
훈련 세트 구성
- 클래스 정의: 보행자, 자동차, 오토바이 3가지 물체를 검출하는 알고리즘을 훈련한다고 가정한다 (배경 클래스는 제외).
- 앵커 박스: 2개의 앵커 박스를 사용한다.
- 격자: 3x3 격자를 사용한다.
- 타겟 벡터: 각 격자 셀에 대한 타겟 벡터 y는 3x3x2x8 차원을 가진다. 8은 5 (Pc, 경계 상자) + 3 (c1, c2, c3)으로 구성된다.
- 타겟 벡터 생성: 9개의 격자 셀 각각에 대해 적절한 타겟 벡터 y를 생성한다.
- 물체가 없는 셀: Pc = 0, 나머지 값은 무시한다.
- 물체가 있는 셀
- 해당 물체와 IOU가 높은 앵커 박스를 선택한다.
- 선택된 앵커 박스에 해당하는 벡터 부분에 물체 정보 (Pc, 경계 상자, 클래스)를 기록한다.
- 훈련: 100x100x3 이미지를 입력으로 받아 3x3x2x8 크기의 결과 부피를 출력하는 신경망을 훈련한다.
예측
- 이미지 입력: 이미지를 신경망에 입력한다.
- 결과 부피 출력: 신경망은 3x3x2x8 크기의 결과 부피를 출력한다.
- 각 셀별 벡터 해석: 각 격자 셀에 대해 8차원 벡터를 해석한다.
- Pc가 0인 경우: 해당 앵커 박스에 대한 예측은 무시한다.
- Pc가 1인 경우: 경계 상자 및 클래스 정보를 추출한다.
테스트 세트 및 비-최댓값 억제
- 테스트 이미지: 새로운 테스트 이미지를 사용한다.
- 신경망 예측: 신경망은 각 격자 셀에 대해 두 개의 경계 상자 (2개의 앵커 박스)를 예측한다.
- 낮은 확률 제거: 낮은 확률 Pc를 가진 예측을 제거한다.
- 클래스별 NMS: 각 클래스 (보행자, 자동차, 오토바이)에 대해 독립적으로 비-최댓값 억제 (NMS)를 수행한다.
- 최종 예측: NMS를 통과한 예측 결과를 최종 감지 결과로 사용한다.
YOLO 알고리즘 요약
YOLO 알고리즘은 효율적인 물체 감지 알고리즘 중 하나이다. 이 알고리즘은 다양한 아이디어를 결합하여 높은 정확도와 빠른 속도를 제공한다.
C4W3L10 Region Proposals
최근 컴퓨터 비전 분야에서는 단순히 이미지 내 물체의 종류를 분류하는 것을 넘어서, 물체의 위치까지 정확하게 파악하는 물체 감지(Object Detection) 기술이 폭발적으로 발전했습니다. 이번 포스팅에서는 물체 감지의 한 핵심 아이디어인 지역 제안(Region Proposal) 알고리즘과, 이를 활용한 R-CNN 계열 알고리즘에 대해 살펴보겠습니다.
물체 감지와 지역 제안의 개념
전통적인 이미지 분류 문제에서는 이미지 전체를 하나의 클래스로 분류한다. 그러나 물체 감지 문제는 한 이미지 내에 여러 개의 물체가 존재할 수 있으며, 각 물체의 종류뿐만 아니라 위치(경계 상자) 정보까지 예측해야 한다.
- 분류(Classification): 이미지에 무엇이 있는지를 예측한다.
- 로컬리제이션(Localization): 물체가 이미지 내에서 어느 위치에 있는지를 찾아내는 문제이다.
물체 감지 문제에서는 이러한 두 작업을 동시에 수행해야 한다. 예를 들어, 자율 주행 자동차에서는 보행자, 자동차, 오토바이 등 여러 객체를 동시에 감지하고, 각각의 위치를 경계 상자로 나타내야 한다.
슬라이딩 윈도와 지역 제안
초기의 아이디어로 슬라이딩 윈도(Sliding Window) 기법이 있었다. 이 방법은 학습된 분류기를 이미지의 모든 영역(윈도)에 적용하여 물체가 있는지 확인하는 방식이다.
하지만 슬라이딩 윈도는 다음과 같은 단점을 가지고 있다
- 비효율성: 이미지 전체의 모든 위치에서 분류기를 실행해야 하므로 계산 비용이 매우 크다.
- 많은 영역의 불필요한 처리: 물체가 없는 영역에도 동일한 연산을 수행하게 되어 낭비가 발생한다.
이 문제를 해결하기 위해 제안된 것이 지역 제안 알고리즘(Region Proposal Algorithm) 이다. 지역 제안은 이미지에서 물체가 존재할 가능성이 높은 몇몇 영역만을 선택하여, 해당 영역에 대해서만 분류기를 실행한다. 예를 들어, R-CNN 알고리즘은 약 2000개의 후보 영역만을 선택하여 그 영역들에 대해 분류기를 적용함으로써, 슬라이딩 윈도에 비해 훨씬 효율적인 처리 속도를 보여준다.
R-CNN: 지역과 합성곱 신경망의 결합
R-CNN(Regions with CNN features)은 지역 제안 알고리즘을 활용하여 물체 감지 문제를 해결하는 대표적인 방법이다. R-CNN의 주요 특징은 다음과 같다.
- 후보 영역 선택: 슬라이딩 윈도 대신 지역 제안 알고리즘(예: Selective Search)을 사용하여 후보 영역을 선택한다.
- 분류 및 경계 상자 회귀: 선택된 각 후보 영역에 대해 합성곱 신경망(CNN)을 적용하여 물체의 존재 여부와 함께, 경계 상자 좌표 \( b_x, \, b_y, \, b_h, \, b_w \ 를 예측한다.
- 출력 구성: 물체가 감지되면 해당 영역에 대해 클래스 레이블과 경계 상자를 출력한다.
R-CNN은 분할 알고리즘을 통해 후보 영역을 선택함으로써, 모든 영역에 대해 분류기를 실행하는 것보다 계산 비용을 크게 줄일 수 있다. 그러나 R-CNN의 단점은 여전히 후보 영역 분류와 경계 상자 회귀를 각각 별도로 처리해야 하므로, 전체 시스템이 느리다는 점이다.
R-CNN의 개선된 변형들
R-CNN의 속도와 효율성을 높이기 위해 여러 개선된 알고리즘들이 제안되었다.
- Fast R-CNN: R-CNN의 단점을 보완하기 위해, 전체 이미지를 한 번만 합성곱 신경망에 통과시켜, 후보 영역의 특징을 한꺼번에 추출하는 방법을 도입했다.
- Faster R-CNN: 후보 영역 생성 자체를 신경망 기반으로 수행하여, 지역 제안 단계의 속도를 크게 향상시켰다.
- YOLO(You Only Look Once): 후보 영역을 따로 선택하지 않고, 한 번의 네트워크 실행으로 물체 감지와 경계 상자 예측을 동시에 수행하는 단일 단계 감지 방식이다.
각 알고리즘은 장단점이 있으나, 지역 제안 아이디어는 여전히 컴퓨터 비전 분야에서 매우 영향력 있는 개념으로 자리잡고 있다.