[RL] Living Penalty
Living Penalty
강화학습을 단순하게 접근했을 때는 최종 블록, 즉 목표 블록에 도달하면 +1 보상을 얻거나 불구덩이에 닿으면 -1 보상을 얻는 것이다.
좀 더 현실적으로 들어가서 게임이 끝나는 지점뿐만 아니라 탐색 과정에서도 보상을 받도록 하는 것이다.
예를 들어 총 게임에서 누군가에게 총을 쏘고 적을 죽였으면 점수를 획득할 수 있을 것이다. 다른 게임에서는 다른 차를 추월하면 점수를 얻을 수도 있을 것이다.
이를 강화학습에도 적용할 수 있다. 이전에 많이 사용했던 미로를 예시로 들어보자.

최종 블록에 +1 보상이 있고 다른 최종 블록에는 -1 보상이 있다.
이외의 나머지 블록에는 -0.04의 보상이 있다고 추가해보자.
그렇다면 에이전트가 돌아다닐수록 - 보상이 누적될 것이고 그렇기 때문에 에이전트는 최대한 빨리 게임을 끝내려고 할 것이다.
4개의 보상 예시를 들어 에이전트의 정책이 어떻게 변할지 보자.
계산은 직접 하지 않고 결과를 추론하기만 할 것이다.
R(s) = 0
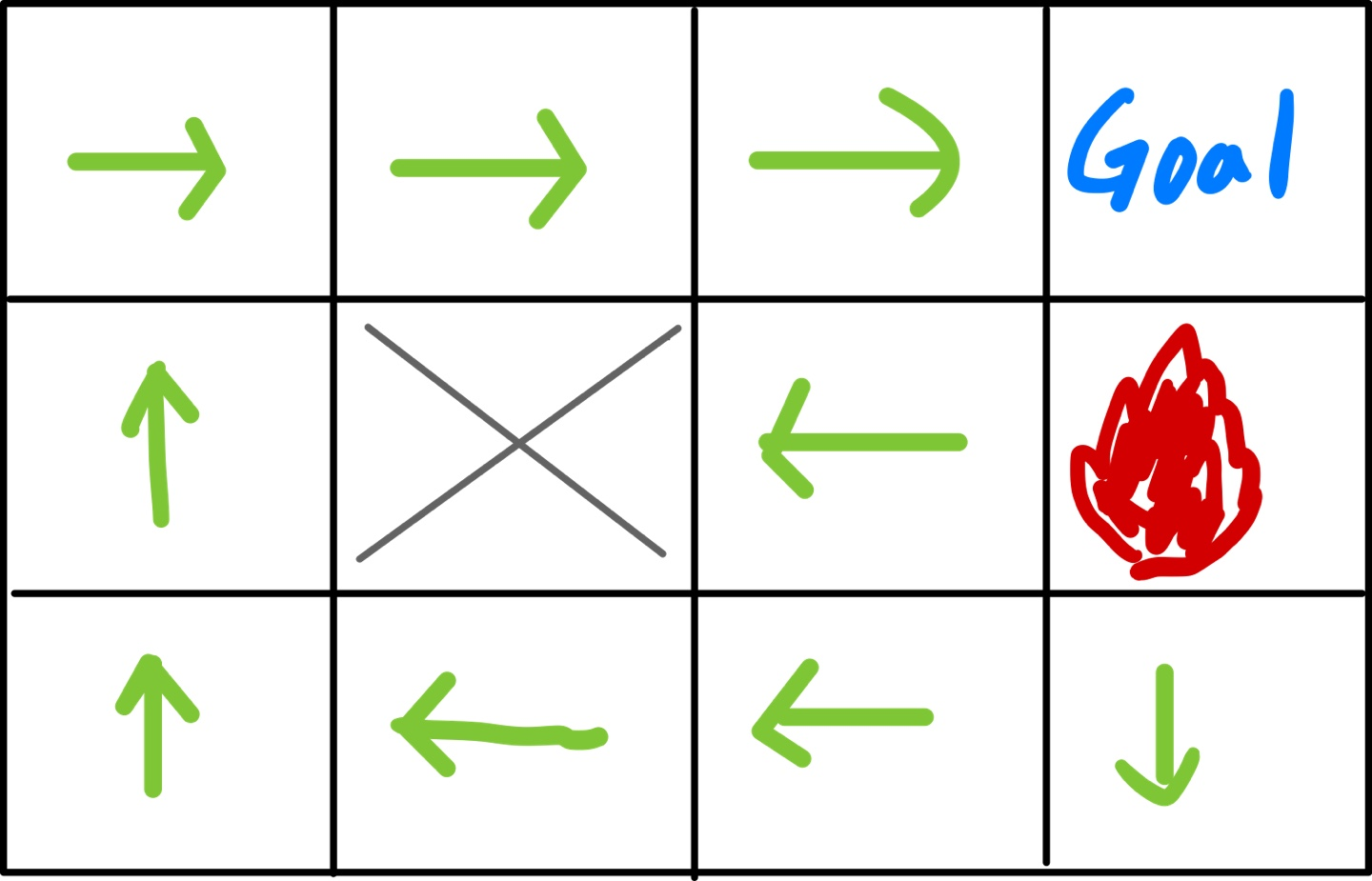
이전에 포스팅했던 예시와 같다. 에이전트가 행동을 할 때 어떤 상태가 되든 보상은 0이다.
페널티를 받지 않으니 원하는 만큼 오래 살아남을 수 있고 경로를 찾아 돌아다닐 수 있는 합리적인 결정을 내린 것이다.
불구덩이 블록에 가는 것보다 당연히 벽처럼 가지 못하는 곳에 있는 것이 훨씬 안전할 것이다.
R(s) = -0.04
이제는 한 단계씩 움직이는 것만드로 -0.04 보상을 받게 할 것이다.

페널티가 없을 때와 비교해보면 벽에 부딪히려고 하지 않고 위로 올라가는 선택을 한다. 벽으로 가는 확률이 80%이고, 불구덩이로 가는 확률이 10%, 위로 올라가는 확률이 10%라고 하면 10% 확률로 불구덩이에 가는 확률을 감수하고 위로 올라가는 선택을 한다. 80% 확률로 벽에 부딪히는 행동을 수행할 때마다 -0.04 보상을 받게 될 것익고, 여러 번 반복하게 된다면 - 보상이 엄청 누적될 것이다.
그래서 에이전트는 벽에 부딪히는 방법의 기댓값이 위험을 감수하고 위로 올라가는 것보다 낮아 위로 가는 선택을 하게 된다.
R(s) = -0.5
이제 리빙 페널티로 -0.5 보상을 받을 경우이다.

-0.04의 보상을 받을 때보다 더 낮은 보상인 -0.5를 받게 된다. -0.5는 두 번만 움직이더라도 불구덩이의 -1 보상과 같아진다.
그래서 에이전트는 최대한 빨리 게임을 끝내고 싶어 할 것이고 에이전트가 짧은 경로의 기댓값이 돌아서 가는 경로의 기댓값보다 더 낮다고 계산하여 진행하게 될 것이다.
R(s) = -2.0
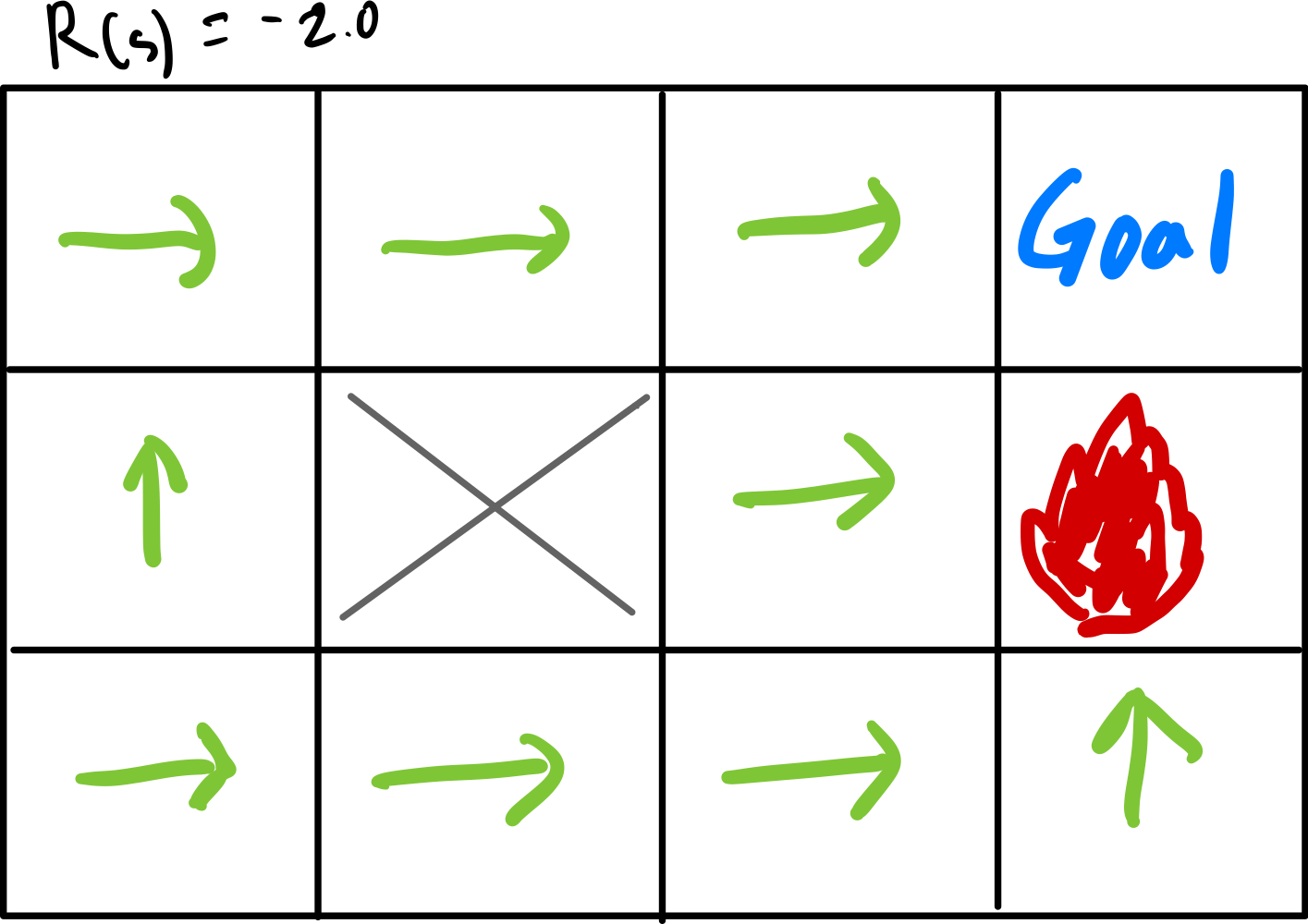
마지막으로 리빙 페널티로 -2.0으로 설정한 것이다.
-2이면 불구덩이 보상이 -1보다 더 작다. 페널티가 너무 높기 때문에 에이전트는 게임을 무조건 빨리 끝내려고 할 것이다.
불구덩이에 닿아서 끝내더라도..
아무리 짧게 간다고 해도 한 번만 움직여도 -1보다 낮은 -2를 받게 될테니 그래서 불구덩이 옆의 블록은 무조건 불구덩이로 바로 닿도록 하여 -2보다 -1 보상을 받도록 하는 것이다.